MiMo Code: Scaling Coding Agents to Long-Horizon Tasks

MiMo Code is a terminal-based coding agent built by Xiaomi's MiMo team on top of OpenCode and open-sourced under the MIT license. It is designed for long-horizon automated programming tasks, with a core focus on how to maintain decision quality and state continuity over dozens or even hundreds of execution steps. This article introduces the core technical design of MiMo Code through three themes: computation, memory, and evolution.
1. Design Motivation
The basic structure of a coding agent is to place a language model inside a runtime and call it in a loop: the model is responsible for reasoning and decision-making, while the runtime manages tools, persists state, and assembles the input for each round. The model itself is stateless—each call starts from a blank slate, and all continuity is provided by the runtime.
For short tasks (typically fewer than 10 turns), this structure works well: simply passing the full conversation history to the model is enough, because the history itself serves as adequate working memory. But as the number of task turns increases, two problems gradually emerge.
First, the context window will eventually be exhausted. No matter how large the window is, dozens of rounds of tool outputs, code snippets, and error logs will eventually fill it up. At that point, part of the history must be compressed or discarded. A common approach is to generate a summary to replace the discarded content. But simple compression continually reinforces nearby information while weakening distant information. This approach runs into an inherent dilemma similar to that of recurrent models such as Mamba: it has state, but cannot look back on demand. What we need is not better compression, but an explicit storage-and-retrieval mechanism that decides what information should be written into persistent structures, and when it should be recalled.
Second, even if the context window is large enough, a model's instruction-following ability declines as input length grows. Useful constraints and intentions are diluted by large volumes of tool output, making it increasingly difficult for the model to extract what it should do next.
We observed that the most prominent bottlenecks vary across different time scales: the quality of single-turn decisions within a session is mainly constrained by computation; the continuity of multi-turn tasks within a session is mainly constrained by state management; and improvement across sessions is mainly constrained by the mechanism for distilling experience. These three time scales correspond exactly to computation, memory, and evolution. MiMo Code is designed around these three themes.
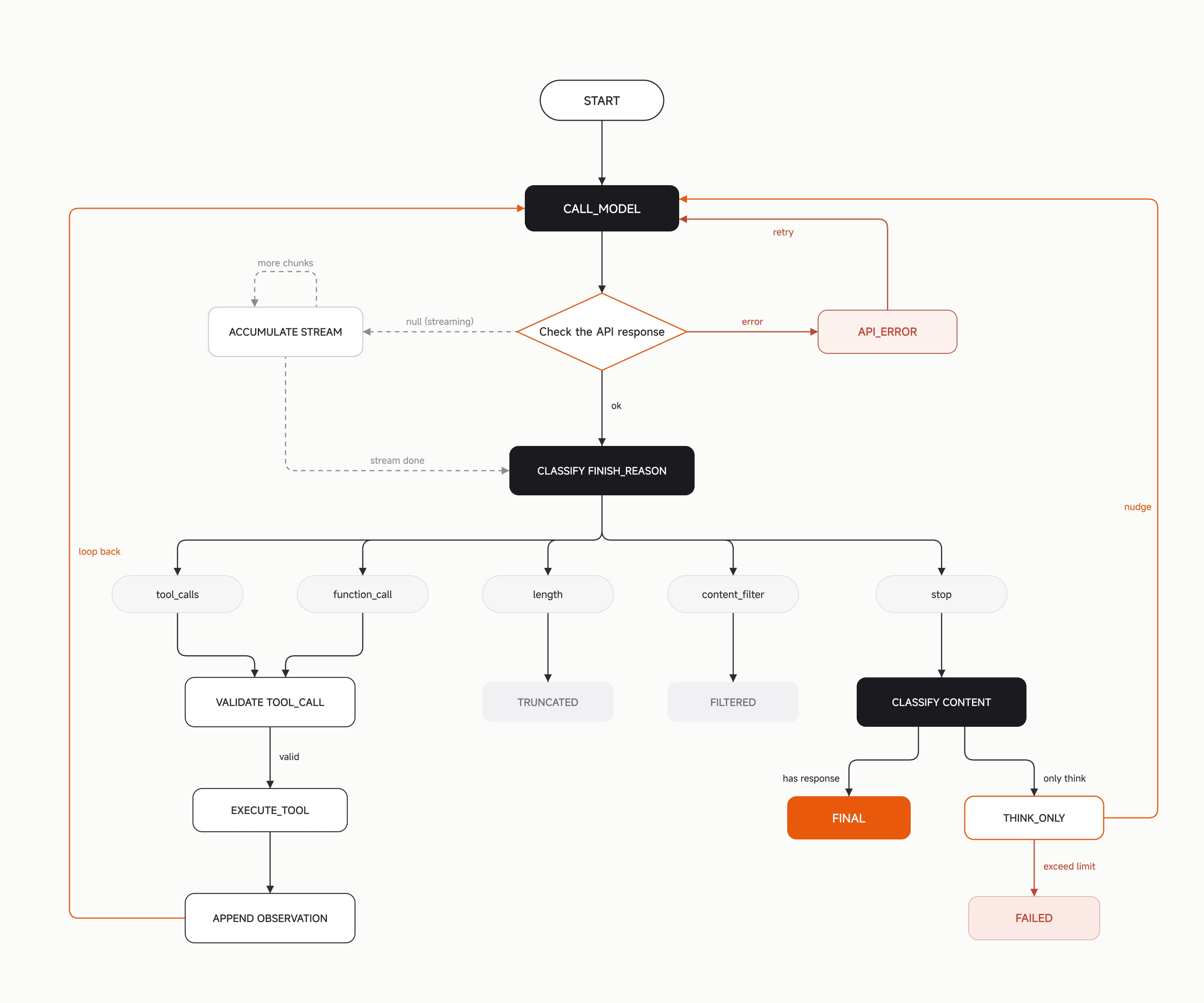
2. Computation: Scaling Single-Turn Reasoning
When a task grows to dozens or even hundreds of steps, the error rate of each individual step compounds over time, while the agent often lacks external corrective signals during long-horizon execution. A direct response is to invest additional computation at different levels of granularity in exchange for reliability: reducing the probability of decision errors at the single-step level, preventing premature termination or directional drift at the task level, and reducing unnecessary back-and-forth overhead at the execution level.
2.1 Parallel Sampling and Selection (Max Mode)
Max Mode generates N candidate solutions in parallel at each turn (N is set to 5 by default). Each candidate independently completes reasoning and tool-call planning, but does not actually execute the plan. The same model is then used as a judge to compare the reasoning process and action plan of all candidates, selecting the best one for execution.
By default, temperature is set to 1, so five independent samples almost never produce identical results. If multiple candidates happen to converge, that itself indicates high confidence in that direction; when candidates differ significantly, having a low-temperature judge select the most robust plan is more reliable than depending on a single sample.
On SWE-Bench Pro, Max Mode improves performance by 10–20% compared with single sampling, at the cost of roughly 4–5 times the token consumption.
Max Mode is currently an experimental feature and must be enabled manually through configuration.
2.2 Independent Completion Verification (Goal)
Max Mode addresses "doing it right"; Goal addresses "finishing it."
A common failure mode in long tasks is that, after seeing prior progress in later turns, the agent tends to prematurely declare that it is "done" or ask a question. This is especially dangerous in automated execution, because there is no human standing by to correct it or provide feedback.
The Goal mechanism works as follows: the user defines a natural-language stopping condition, such as "all tests pass and the code has been committed." Whenever the agent attempts to terminate, the system automatically launches an independent model call to review the full conversation history and determine whether the condition has truly been satisfied. If not, it feeds back the specific gap to the agent and lets it continue; if the task is confirmed to be impossible, it is marked as impossible.
This verifier does not participate in the actual work, so it does not develop an alignment bias toward the parts the agent has already completed. Each time, it receives exactly the same context as the agent, including the actual tool outputs.
In practice, false blocking—where the condition is already satisfied but the verifier judges that it is not—is more common than false passing. This mainly occurs when tests fail due to environment issues. Overall, the probability of an infinite loop is below 0.5%, and the system can automatically exit after reaching the limit.
Max Mode and Goal represent two orthogonal directions of test-time compute: Max Mode is parallel, spending N times the compute on the same step to select the best option; Goal is serial, spending more time on self-checking and continued execution within the same task. The two can be enabled simultaneously.
2.3 Tool-Call Syntax
The format through which the model issues tool calls directly affects accuracy and token efficiency. Some models (especially the GPT-5.5 series) have a relatively high formatting error rate when outputting structured JSON, and XML performs slightly better than JSON. We ultimately found that a constrained command-line syntax requires fewer tokens to express the same tool-call intent and also produces fewer formatting errors, because most models have been trained on dense shell-environment data. The syntax is intentionally constrained: it does not support pipes, redirection, or variable expansion. The goal is to borrow the conciseness of the shell, not to give the model an uncontrolled execution environment.
MiMo Code has not yet migrated tool calls to this format. The replacement may be gradually completed in future versions.
2.4 Large-Scale Parallel Orchestration (Dynamic Workflow)
The mechanisms above address quality issues at the single-round and single-Agent levels. When the task scale becomes large enough—for example, migrating an entire project from one programming language to another—and dozens or even hundreds of parallel work units need to be coordinated simultaneously, round-by-round tool calls are no longer sufficient.
The traditional approach is to write the process into SKILL.md and use natural language to tell the model: "do A first, then do B, and if C happens, do D." This works in simple scenarios, but systematically fails in complex workflows: context compression may swallow steps, the model may skip certain stages, branching and retry logic depend on the model's judgment rather than being guaranteed by code, and the same workflow may follow different execution paths across two runs. The fundamental problem is that orchestration logic exists in natural language, and natural language is ambiguous, forgettable, and unverifiable.
Dynamic Workflow turns orchestration logic from prompt into code. The main Agent generates a JavaScript script, which is executed deterministically inside an isolated sandbox. The script dispatches sub-Agents through agent() and controls concurrency through parallel() / pipeline()—an if statement will not forget a branch, a for loop will not exit prematurely, and a barrier will not miss a sub-Agent. The model's judgment is used only where it should be used, such as understanding and generating code, rather than being wasted on flow control.
Our implementation is compatible with the core semantics of Anthropic Dynamic Workflow, and extends it in several ways. The workflow() primitive allows scripts to call other scripts, so orchestration logic can be organized into reusable and composable building blocks. The result of each agent() call is synchronously written to disk, allowing the process to recover from logs after an interruption rather than rerunning from scratch. Files can also be read and written directly inside the sandbox. We believe that many skills currently defined in prompt form will gradually evolve into workflow scripts in code form. When every step of a process must be executed, branch conditions must be precise, and retry logic must be reliable, it should be guaranteed by code rather than natural language.
3. Memory: Maintaining State Continuity Across Multi-Turn Tasks
Scaling single-turn computation can reduce the error rate of each step, but it does not solve the core problem of multi-turn tasks: the context will eventually run out. This section discusses how to let a logical session extend indefinitely while keeping each physical window bounded.
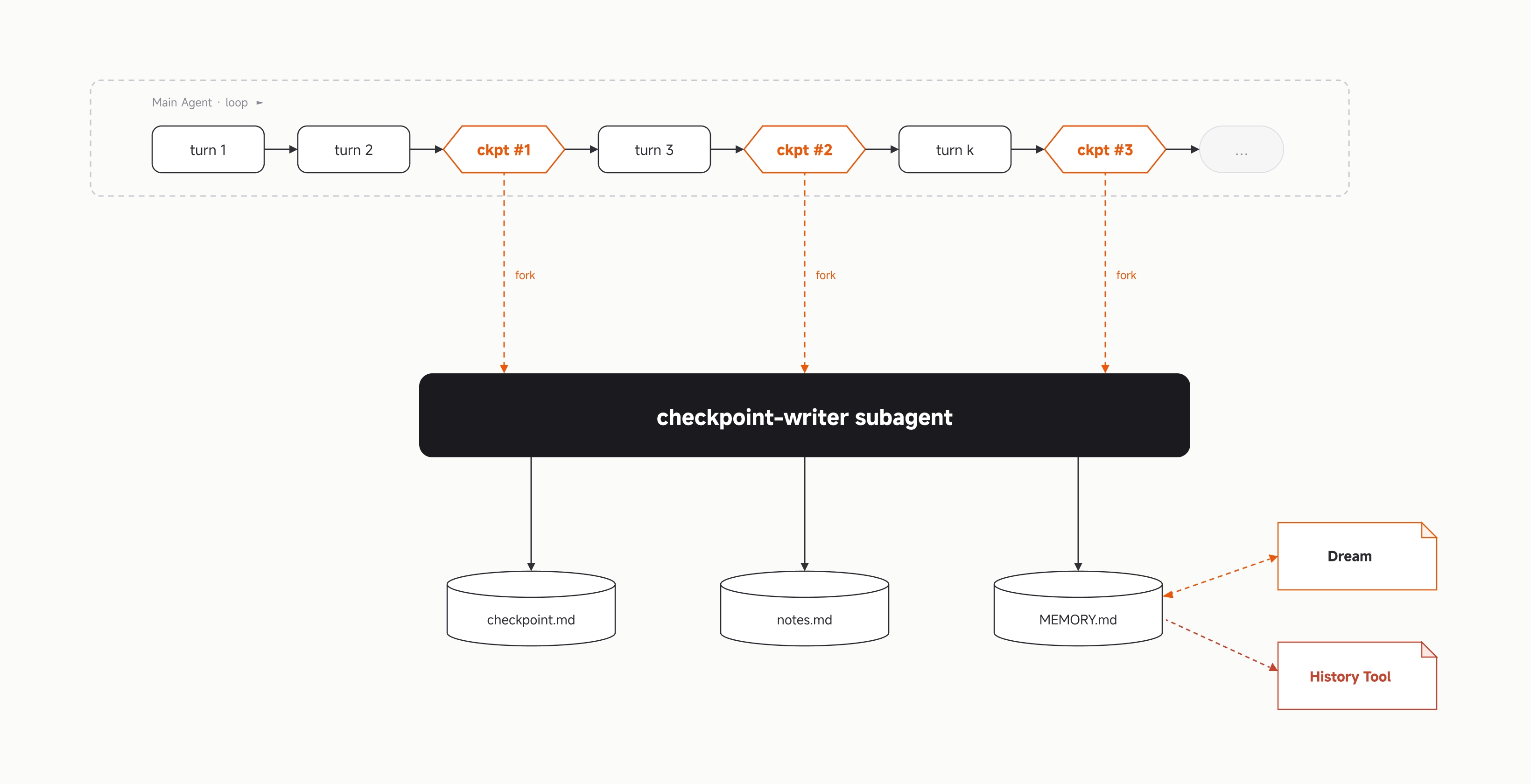
3.1 Cycle: The Basic Unit of an Unbounded Session
Imagine a session as a sequence of turns arranged from left to right. The window has an upper limit, the turns keep accumulating, and the window will eventually fill up. Without intervention, the session either ends when it reaches the limit or quietly degrades.
Before the limit is reached, the runtime intervenes at several fixed positions. We call these positions checkpoints. At each checkpoint, the runtime dispatches an independent writer subagent: it reads the conversation so far and writes a structured state file to disk. The main agent continues working while the writer runs concurrently, and the two do not interfere with each other.
When the window approaches the true upper limit, the runtime performs a rebuild: it cuts off the current window, opens a new one, and reconstructs the context using the persisted files as seeds. The main agent wakes up in the new window with the state already laid out in front of it, then continues working. From the model's perspective, the conversation has never been interrupted; from the runtime's perspective, a new physical window has begun.
A sequence of turns that has been checkpointed and ultimately ends with a rebuild is a cycle. There is no upper bound on the number of cycles—each cycle is limited by the size of the physical window, but the logical session is a chain of cycles, and that chain has no maximum length.
3.2 Why Extract Early
A natural intuition is to delay extraction until the window is almost full. We found that this is exactly backwards.
First, model capability degrades under high context utilization. This is known in the literature as "lost in the middle": as the input grows longer, attention to the middle portion declines, and the reliability of structured extraction drops significantly. Asking the model to perform the most critical compression at the very moment when its compression ability is degrading is a bad trade-off.
Second, extraction itself requires space. The writer must read the history, maintain its interpretation, and produce structured output—all within the same window. At 95% utilization, there is no room left to think; at 30% utilization, there is ample room.
Therefore, checkpoints are triggered far below the upper limit—roughly at 20%, 45%, and 70% of the configured budget. Each trigger is an incremental update to the previous one; none of them is a one-shot summary. The final rebuild near the upper limit is not a rushed compression, but the moment when the structured records accumulated along the way are turned into working context.
3.3 Writer: An Extractor Independent of the Main Agent
The most natural reaction is to let the main agent maintain its own notes. We found that this does not hold up in long tasks: asking a model that is currently debugging a tricky issue to also maintain a structured log often causes it to do both tasks worse.
So we impose a different constraint: the main agent does not maintain its own memory. Extraction is moved entirely out of the main loop, triggered by the runtime and performed by an independent writer subagent—one that does not share the main agent's attention or token budget.
The writer writes a checkpoint file with a fixed structure (11 fields: current intent, next action, working constraints, task tree, current work, involved files, cross-task discoveries, errors and fixes, runtime state, design decisions, and miscellaneous notes), and updates project-level memory when needed. For each structured file, exactly one actor is allowed to write to it—single-writer is the simplest invariant for preventing inconsistent state caused by concurrent writes.
3.4 Four Layers of Memory
The writer does not write only one file. It maintains a layered memory system, with each layer having a different lifecycle:
- Session memory (checkpoint.md): Lives only within the current logical session and records the complete working state of that session.
- Project memory (MEMORY.md): Persistent project-level knowledge—architectural decisions, user rules, and repeatedly verified technical facts. When an observation stabilizes across multiple session checkpoints, the writer promotes it from the session layer to this layer.
- Global memory: User-level preferences that apply across projects.
- History: The full SQLite trace of each session—the raw text of every message and every tool call, stored without indexing. When a detail cannot be found in structured memory, the agent uses the history tool to trace back to the original record.
The relationship among the four layers is as follows: the upper layers are more refined, more persistent, and smaller; the lower layers are more complete, larger, and slower. The writer is responsible for distilling upward, while history serves as the fallback below.
The main agent has read-only access to structured files, with one exception: notes.md, a session-level free-form scratchpad. The main agent can append scattered findings to it at any time; at each checkpoint, the writer reads it, routes its content into the appropriate structured fields, and then clears it. This is the only write channel available to the main agent.
3.5 Rebuild Injection
When the runtime performs a rebuild, it assembles the persisted files into a layered prompt and injects it into the new window, with an independent token limit for each section. The approximate order is: task list (the agent first needs to know what it is supposed to do) → session checkpoint → verbatim slices of recent user messages (to prevent the writer's rewriting from drifting away from the user's original intent) → project memory → global memory → notes → an index of memory file paths that can be read on demand → a tail reminder that tells the agent what to do next.
Even if every section reaches its limit, the total injected content is kept within roughly 65K tokens—well within the working budget of any reasonable context window. After recovering its state from this information, the agent continues working directly, without needing to reconfirm the goal or reread files that have already been processed.
4. Evolution: Continuous Improvement from Experience
The previous two sections address how to work well within a single turn and a single session. But in real development, a user may interact with the same project dozens or even hundreds of times. If all experience is lost after each session ends, the agent can never accumulate from past work; it has to rediscover the same project constraints and repeat the same mistakes every time.
4.1 Project Memory
MiMo Code maintains a project-level memory file (in Markdown format), persistently storing knowledge across sessions: project background, rules explicitly specified by the user, architectural decisions and their rationale, and repeatedly verified technical facts.
The core reason for choosing files rather than a pure vector database is reviewability: once memory affects the agent's subsequent behavior, the user needs to be able to see what the system has remembered, delete incorrect entries, and modify outdated knowledge. Files can be directly manipulated by standard read/write tools without requiring a dedicated interface for every maintenance operation. A full-text index provides fast retrieval on top of the files.
The checkpoint writer only updates the current session's checkpoint each time it is triggered, and write permissions are enforced at the code level. The background writer can only write to specified file paths, and any out-of-bounds write is directly rejected.
4.2 Memory Maintenance (Dream and Distill)
The project memory file grows over time. Without maintenance, outdated entries, duplicate records, and invalid file references gradually accumulate, lowering the signal-to-noise ratio.
Dream is automatically triggered every 7 days. An independent agent reads historical session conversations and the existing memory file, then performs merging, deduplication, path-validity verification, and compression—converging scattered memories into a compact representation of the current state and updating global memory.
Distill is automatically triggered every 30 days. It is also performed by an independent agent that reads historical sessions, but its focus is not knowledge—it is process. It identifies recurring work patterns and solidifies them into reusable skills, CLI commands, custom agents, SOP documents, and similar artifacts.
5. Evaluation
5.1 Offline Benchmarks
The table below shows the performance of MiMo Code and Claude Code with different models on three mainstream benchmarks.

MiMo Code + MiMo-V2.5-Pro outperforms Claude Code + Claude Sonnet 4.6 across all three evaluations. It should be noted, however, that these benchmarks still measure one-shot problem-solving ability on individual repository-level issues. Most of MiMo Code's design goals—multi-turn memory, background state maintenance, completion verification, and cross-session evolution—mainly show their value in real development scenarios that continue for dozens of turns. These advantages can only be fully reflected in actual use.
5.2 Human Double-Blind A/B Testing
To address the limitations of offline benchmarks, we built a human-in-the-loop double-blind A/B evaluation: in developers' own real projects, two anonymous coding agents are launched in parallel for the same task. After they complete the task independently, the developer scores them, with automatic trajectory scoring and diff quantification used for triangulation.
During the reporting period, the internal beta covered 576 developers and 474 real private repositories, producing 1,213 A/B pairs with clear win/loss judgments, comparing the end-to-end real development experience of MiMo Code and Claude Code under the same target model.
In the evaluation, we found that MiMo Code's advantage grows as task complexity increases: when the number of execution steps is within 200, the win rates of the two systems are close to 50%; when the number of steps exceeds 200 (including multi-turn user interaction), MiMo Code's win rate rises to over 65%.
6. Usage
# One-line install, or install via npm
curl -fsSL https://mimo.xiaomi.com/install | bash
npm install -g @mimo-ai/cliOn first launch, MiMo Code guides the user through selecting a model access method: MiMo Auto (free for a limited time, based on MiMo-V2.5 and supporting a 1-million-token context), Xiaomi MiMo platform login, importing from Claude Code configuration, or using a custom model.