MiMo Code:将编程 Agent 扩展到长程任务

MiMo Code 是小米 MiMo 团队基于 OpenCode 构建的终端编程 Agent,MIT 协议开源。它针对长程自动化编程任务设计,核心关注点是:如何在几十甚至上百步的持续执行中保持决策质量和状态连续性。本文围绕计算、记忆、进化三个主题,介绍 MiMo Code 的核心技术设计。
1. 设计动机
一个编程 Agent 的基本结构是将语言模型放入一个运行时中循环调用:模型负责推理和决策,运行时负责管理工具、持久化状态、组装每一轮的输入。模型本身是无状态的——每次调用都从空白开始,所有连续性由运行时提供。
对于短任务(10 轮以内),这个结构工作良好:将完整对话历史传给模型即可,历史本身就是足够好的工作记忆。但随着任务轮次增加,两个问题逐渐显现:
第一,上下文窗口终会耗尽。无论窗口多大,持续几十轮的工具输出、代码片段、报错日志会将其填满,此时必须压缩或丢弃部分历史。常见做法是生成一段摘要来替代被丢弃的内容。但简单的压缩会不断强化邻近信息、衰减远处信息,这样的方式会遇到类似状态空间模型(如 Mamba)的固有困境:有状态但无法按需回溯。我们需要的不是更好的压缩,而是一套显式的存储-检索机制,决定什么信息在什么时候被写入持久结构、什么时候被召回。
第二,即使窗口足够大,模型的指令遵循率也会随输入长度下降。有用的约束和意图被大量工具输出稀释,模型越来越难从中提取出当前应该做什么。
我们观察到,在不同时间尺度上构成最突出的瓶颈分别是:同 session 的单轮决策质量主要受限于计算量,同 session 的多轮任务连续性主要受限于状态管理,跨 session 的任务改进主要受限于经验的提炼机制。而这三种时间尺度,恰好分别对应:计算、记忆、进化,MiMo Code 的设计围绕这三个主题展开。
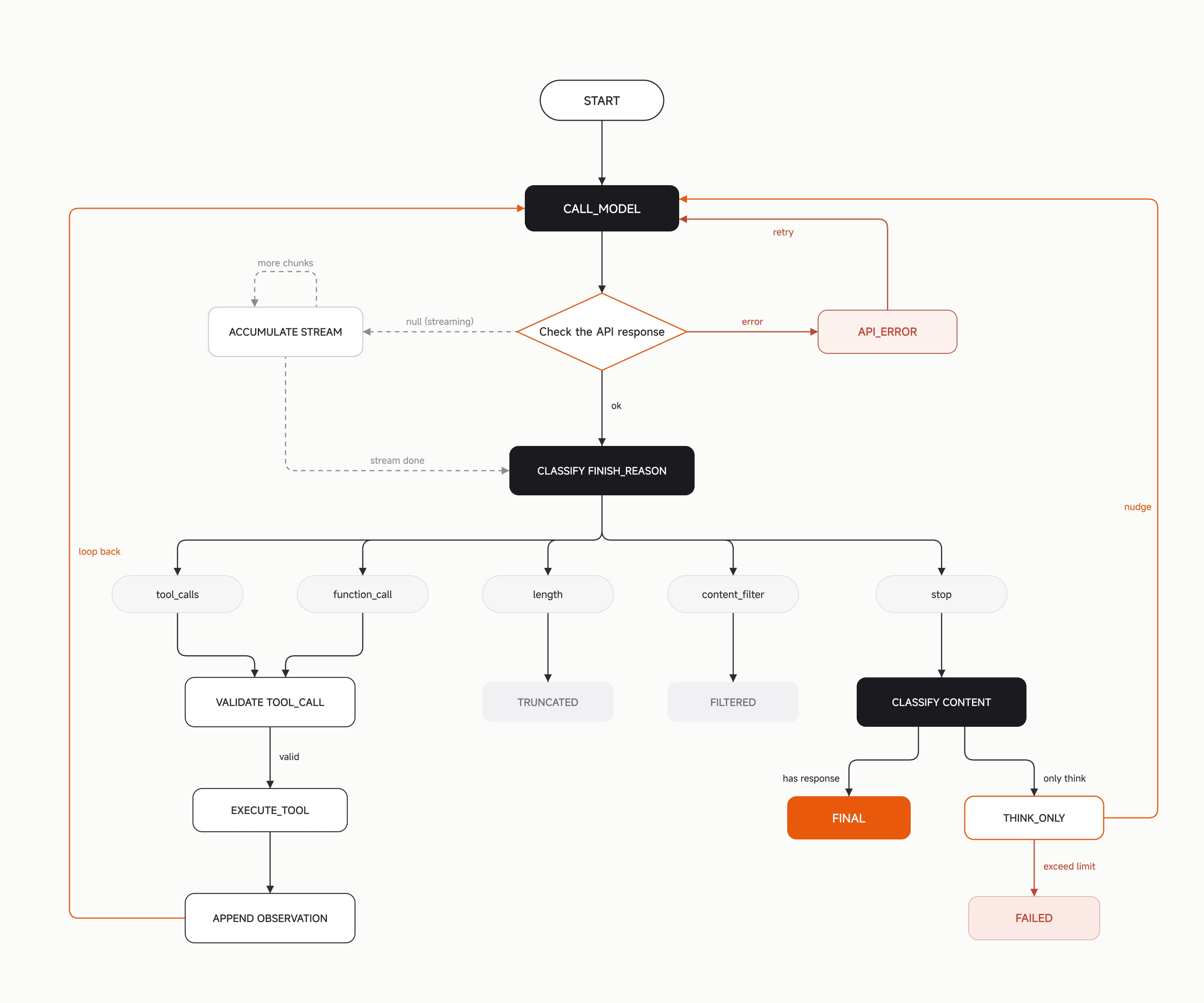
2. 计算:扩展单轮推理的计算量
当任务规模达到几十甚至上百步时,每一步的错误率会被累积放大,而 Agent 在长程运行中缺乏外部纠正信号。一个直接的应对思路是,在不同粒度上投入额外的计算来换取可靠性:单步层面降低决策出错的概率,任务层面防止过早终止或方向偏离,执行层面减少不必要的往返开销。
2.1 并行采样选优(Max Mode)
Max Mode 在每一轮并行生成 N 个候选方案(默认 N=5),每个候选独立完成推理和工具调用规划,但不实际执行。然后由同一个模型作为 judge,对比所有候选的推理过程和行动计划,选出最优的一个执行。
默认使用 temperature=1,5 次独立采样几乎不会产出相同结果。如果多个候选方案恰好收敛,这本身就表明该方向的置信度高;而当候选之间差异较大时,由低温度的 judge 从中选出最稳健的方案,比依赖单次采样更可靠。
在 SWE-Bench Pro 上,Max Mode 相比单次采样提升 10-20%,代价是约 4~5 倍的 token 消耗。
目前 Max Mode 仅为实验性功能,需要通过手动配置开启。
2.2 独立完成度验证(Goal)
Max Mode 解决的是"做对",Goal 解决的是"做完"。
长任务中有一种常见的失败模式:Agent 在后续轮次看到之前已有的进展,就倾向于提前宣称"完成了"或进行提问。这在自动化运行中尤其危险,因为没有人类在旁边纠正和反馈。
Goal 的机制是,用户设定一个自然语言描述的停止条件(例如"所有测试通过且代码已提交")。Agent 每次尝试终止时,系统自动发起一次独立的模型调用来审查完整对话历史,判断条件是否真正满足。如果未满足,将具体差距反馈给 Agent 并让它继续;如果确认无法完成,则判定为不可能。
这个验证者不参与实际工作,因此不会对 Agent 已完成的部分产生认同偏差,它每次获得与 Agent 完全相同的上下文(包括工具的实际输出)。
实际运行中,误拦(条件已满足但验证者认为未满足)比漏放更常见,主要发生在环境问题导致的测试失败上,整体死循环概率小于 0.5%,并且到达上限后可自动退出。
Max Mode 和 Goal 代表了 test-time compute 的两个正交方向:Max Mode 代表并行,同一步花 N 倍算力选最优;Goal 代表串行,在同一个任务上做更长的自我检查和执行。两者可以同时启用。
2.3 工具调用语法
模型通过什么格式发出工具调用,直接影响准确率和 token 效率。部分模型(特别是 GPT 5.5 系列)在输出结构化 JSON 时格式错误率较高,XML 相比 JSON 效果略好。我们最终发现采用受限的命令行语法,同样的调用意图用这种格式表达所需的 token 更少,格式错误也更低,因为大部分模型在 shell 环境下的训练数据密度高。语法是刻意受限的:不支持管道、重定向、变量展开,目的是借用 shell 的简洁性,而非给模型一个不受控的执行环境。
目前 MiMo Code 尚未将工具调用迁移至此格式,后续版本中可能将逐步完成替换。
2.4 大规模并行编排(Dynamic Workflow)
上述机制解决的是单轮和单 Agent 的质量问题。当任务规模足够大(例如将整个项目从一种语言迁移到另一种语言),需要同时协调几十甚至上百个并行工作单元时,逐轮的工具调用不再够用。
传统的做法是把流程写进 SKILL.md,用自然语言告诉模型"先做 A,再做 B,如果 C 就做 D"。这在简单场景下能用,但在复杂流程中会系统性失效:上下文压缩可能吞掉步骤、模型可能跳过某些环节、分支和重试逻辑靠模型判断而非代码保证、同一流程两次执行路径不同。本质问题是:编排逻辑以自然语言存在,而自然语言是模糊的、可遗忘的、不可验证的。
Dynamic Workflow 把编排逻辑从 prompt 变成代码。主 Agent 生成一段 JavaScript 脚本,在隔离沙箱中确定性执行。脚本通过 agent() 派出子 Agent,通过 parallel() / pipeline() 控制并发——if 不会忘记分支,for 不会提前退出,barrier 不会漏掉子 Agent。模型的判断力只用在它该用的地方(理解代码、生成代码),而不浪费在流程控制上。
我们的实现兼容 Anthropic Dynamic Workflow 的核心语义,在此基础上做了几项扩展:workflow() 原语允许脚本调用其他脚本,使编排逻辑可以被组织为可复用、可组合的积木;每个 agent() 调用的结果同步落盘,进程中断后可从日志恢复而非从头重跑;沙箱内可直接读写文件。我们认为,目前以 prompt 形式定义的许多 skill,未来会逐步演变为这种代码形式的 workflow 脚本——当一个流程的每一步都必须执行、分支条件必须精确、重试逻辑必须可靠时,它就该用代码而非自然语言来保证。
3. 记忆:维持多轮任务的状态连续性
扩展单轮的计算量可以降低每一步的错误率,但不解决多轮任务的核心问题:上下文终会耗尽。这一节讨论的是:如何让一个逻辑会话无限延伸,而每个物理窗口保持有界。
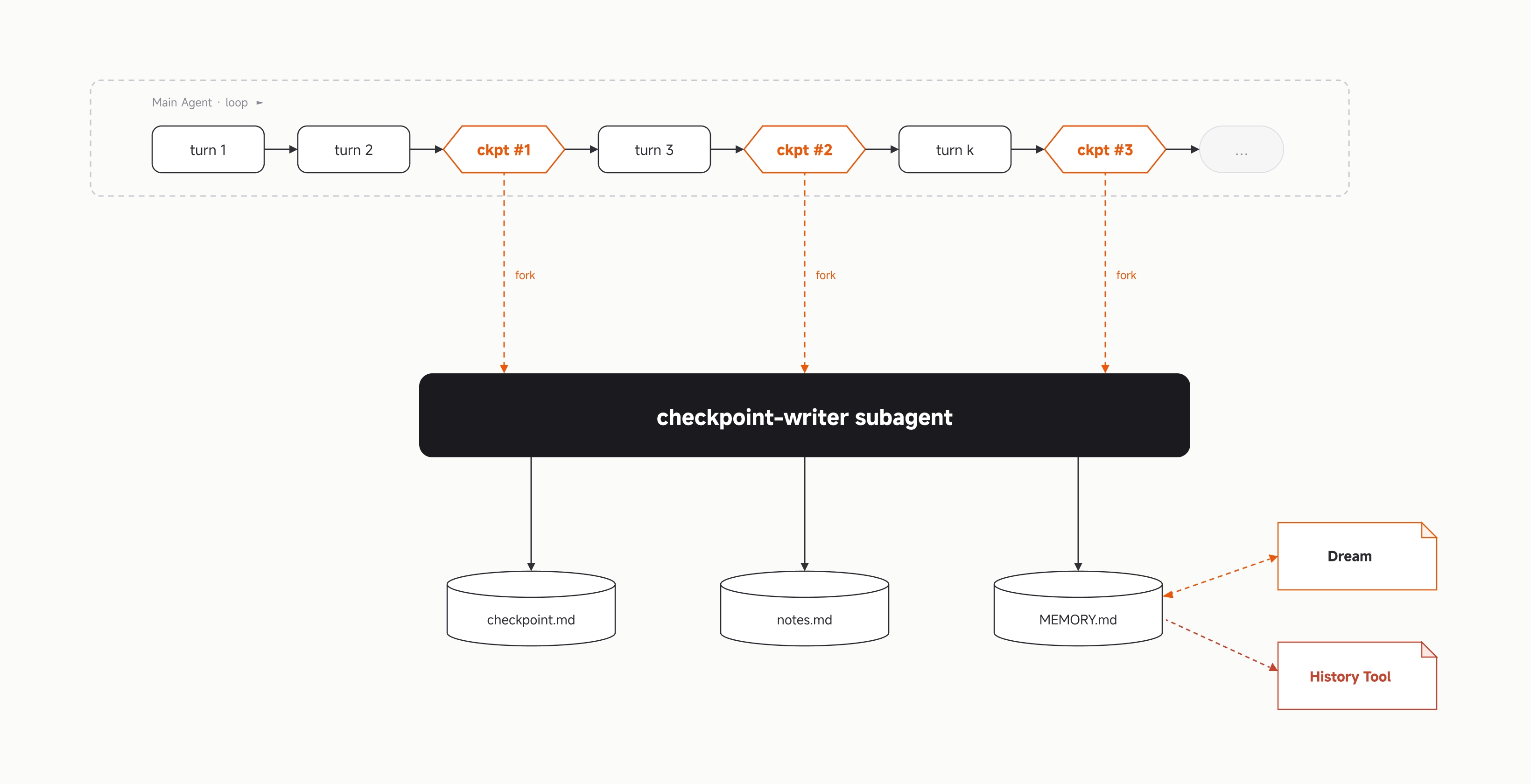
3.1 Cycle:无界会话的基本单元
把会话想象成一串从左到右排开的 turn。窗口有上限,turn 在累积,窗口终会被填满。如果不干预,会话到达上限时要么结束,要么悄悄退化。
运行时在到达上限之前的几个固定位置介入。我们称这些位置为 checkpoint。每个 checkpoint 处,运行时派出一个独立的 writer subagent:读取迄今的对话,将一份结构化状态写入磁盘。主 Agent 继续工作,writer 并发执行,互不干扰。
当窗口接近真正的上限,运行时执行一次 rebuild:切断当前窗口,开启新窗口,用已持久化的文件作为种子重建上下文。主 Agent 在新窗口中醒来,状态已摆在面前,继续工作。从模型视角看,对话从未中断;从运行时视角看,一个新的物理窗口已经开始。
一段被 checkpoint 打过点、最终以 rebuild 收尾的 turn 序列,是一个 cycle。Cycle 没有数量上限——每一个 cycle 受限于物理窗口大小,但逻辑会话是 cycle 的链,而那条链没有最大长度。
3.2 为什么提早提取
一种自然的直觉是把提取拖到窗口快满时。我们发现这恰好是反着的。
第一,模型在高上下文利用率下能力会衰减。这在文献中被称为 "lost in the middle":随着输入变长,对中段材料的注意力下降,结构化提取的可靠性显著降低。要求模型在它的压缩能力正在退化的时刻去做最关键的压缩,是一桩划不来的交易。
第二,提取本身需要空间。Writer 必须读完历史、维持解读、写出结构化输出——全部在同一个窗口里。95% 利用率下已无处思考;30% 利用率下则游刃有余。
因此 checkpoint 在远低于上限处触发——大致在已配置预算的 20%、45%、70%。每一次触发都是对前一次的增量更新,没有任何一次是孤注一掷的总结。最末尾接近上限的那次 rebuild,不是一次仓促的压缩,而是将一路记下来的结构化记录变现的时刻。
3.3 Writer:独立于主 Agent 的提取者
最自然的反应是让主 Agent 自己维护笔记。我们发现这在长任务面前撑不住:要求一个正在调棘手 bug 的模型同时维护结构化日志,往往会在两件事上各做差一件。
所以我们换一种约束:主 Agent 不维护自己的记忆。 提取被完全移出主循环,由运行时触发,由一个独立的 writer subagent 完成——它不与主 Agent 共享注意力或 token 预算。
Writer 写入一份固定结构的 checkpoint 文件(11 个字段:当前意图、下一步动作、工作约束、任务树、当前工作、涉及文件、跨任务发现、错误与修复、运行时状态、设计决策、杂项笔记),以及按需更新项目级记忆。对每个结构化文件,只有恰好一个 actor 被允许写入——single-writer 是防止并发写入产生不一致状态的最简不变量。
3.4 四层记忆
Writer 不只写一个文件,它维护一个分层的记忆体系,每一层有不同的生命周期:
- Session 记忆(checkpoint.md):只在当前逻辑会话内存活,记录这次会话的完整工作状态。
- Project 记忆(MEMORY.md):项目级持久知识——架构决定、用户规则、反复验证过的技术事实。当某条观察在多次 session checkpoint 中稳定下来,writer 将其从 session 层提升到这里。
- Global 记忆:用户级偏好,跨项目生效。
- History:每个会话的完整 SQLite 轨迹——每条消息、每次工具调用原文存储,不做索引。当结构化记忆中找不到某个细节时,Agent 通过 history 工具回溯到原始记录。
四层之间的关系是:上层越来越精炼、越来越持久、越来越小;下层越来越完整、越来越庞大、越来越慢。Writer 负责向上提炼,history 负责向下兜底。
主 Agent 对结构化文件只有读权限,但有一个例外:notes.md,一个会话级的自由格式 scratchpad。主 Agent 可以随时往里 append 零散发现,writer 在每次 checkpoint 时读取它、将内容路由到对应的结构化字段,然后清空。这是主 Agent 唯一被允许的写入通道。
3.5 Rebuild 注入
当运行时执行 rebuild 时,它将持久化的文件组装为一个分层的 prompt 注入新窗口,每一段有独立的 token 上限。大致顺序为:任务清单(Agent 首先需要知道自己该做什么)→ session checkpoint → 最近用户消息的逐字切片(防止 writer 的改写偏离用户原意)→ 项目记忆 → 全局记忆 → notes → 可按需读取的 memory 文件路径索引 → tail reminder(告诉 Agent 下一步该做什么)。
即使每段都顶满上限,注入总量也控制在约 65K token 以内——在任何合理窗口的工作预算范围内。Agent 从这些信息中恢复状态后直接继续工作,不需要重新确认目标,不需要重读已处理的文件。
4. 进化:从经验中持续改进
前两节我们解决的是"如何在单轮和单 session 内做好工作"。但实际开发中,用户与同一个项目交互几十次甚至上百次。如果每次 session 结束后所有经验都丢失,Agent 永远无法从过去的工作中积累,每次都要重新发现同样的项目约束、试同样的错。
4.1 项目记忆
MiMo Code 维护一个项目级的记忆文件(Markdown 格式),持久保存跨 session 的知识:项目背景、用户明确要求的规则、架构决定及其理由、反复验证过的技术事实。
选择文件而非纯向量数据库,核心原因是可审查性:记忆一旦影响 Agent 的后续行为,用户就需要能看到系统记住了什么、删除记错的条目、修改过时的知识。文件可以被标准的读写工具直接操作,不需要为每种维护操作开发专用接口。全文索引在文件之上提供快速检索能力。
检查点写入器在每次触发时仅更新当前 session 的检查点,写入权限也在代码层面强制约束:后台写入器只能写入指定的文件路径,越界写入直接拒绝。
4.2 记忆整理(Dream 与 Distill)
项目记忆文件会随时间增长。如果不加维护,过时的条目、重复的记录、失效的文件引用会逐渐积累,降低信噪比。
Dream 每 7 天自动触发,由独立 Agent 读取历史 session 对话和现有记忆文件,执行合并、去重、验证路径有效性和压缩,将分散的记忆收敛为一份紧凑的当前状态,并更新全局记忆。
Distill 每 30 天自动触发,同样由独立 Agent 读取历史 session,但关注的不是知识而是流程——识别反复出现的工作模式,将其固化为可复用的 skill、CLI 命令、自定义 Agent 或 SOP 文档等。
5. 评测
5.1 离线基准
下表为 MiMo Code 和 Claude Code 搭配不同模型在三个主流 Benchmark 上的表现。

MiMo Code + MiMo-V2.5-Pro 在三项评测中均优于 Claude Code + Claude Sonnet 4.6。需要说明的是,这些 Benchmark 衡量的仍是对单个仓库级问题的一次性解决能力。MiMo Code 的多数设计目标——多轮记忆、后台状态维护、完成度验证、跨 session 进化——主要体现在持续几十轮的真实开发场景中,这些优势需要在实际使用中才能充分体现。
5.2 真人双盲 AB 测试
为弥补离线基准的不足,我们构建了一套真人在环的双盲 AB 评测:在开发者自己的真实项目中,针对同一任务并行启动两个匿名编码 Agent,独立完成后由开发者打分,并辅以自动轨迹打分与 diff 量化进行三角互证。
报告期的内部众测覆盖 576 名开发者、474 个真实私有仓库,共形成 1,213 个有明确胜负判定的 AB 配对,在同一目标模型下对比 MiMo Code 与 Claude Code 的端到端真实开发体验。
在测评中我们发现,MiMo Code 的优势随任务复杂度增长而放大:当执行步数在 200 步以内时,两者胜率接近 50%;当步数超过 200(包含多轮用户交互)后,MiMo Code 胜率升至 65% 以上。
6. 使用
# 一行安装,或通过 npm 安装
curl -fsSL https://mimo.xiaomi.com/install | bash
npm install -g @mimo-ai/cli首次启动会引导选择模型接入方式:MiMo Auto(限时免费,基于 MiMo-V2.5,支持 100 万 token 上下文)、小米 MiMo 平台登录、从 Claude Code 配置导入、或自定义模型。