MiMo-V2.5 系列推理全链路优化:将 Hybrid SWA 效率推向极致
MiMo V2.5 系列模型(包含 MiMo-V2.5、MiMo-V2.5-Pro 等)融合了多个架构特点:Hybrid Sliding Window Attention(Hybrid SWA)通过混合窗口注意力将 KVCache 存储降至 Full Attention 的约 1/7;MoE 以稀疏激活在保持模型容量的同时降低单 token 计算成本;多模态 Encoder 支持视觉、音频、视频等跨模态理解。三者叠加,赋予 MiMo-V2.5 系列模型在长上下文与多模态场景下显著的效果与效率潜力。
从 MiMo-V2 模型设计之初,我们就有一个非常明确的目标:训练出一个在长文推理场景下既足够强、又足够高效的模型。但这两个目标在工程上天然存在张力。强推理能力意味着模型需要具备对长距离依赖关系的建模能力,而这通常对应着更大规模的注意力计算与更高昂的 KVCache 开销。在传统 Full Attention 架构中,Attention 的计算量与 KVCache 存储都会随上下文长度快速增长,使长上下文训练与推理的成本迅速变得不可接受。Hybrid SWA 的核心思想是在局部窗口注意力(Sliding Window Attention, SWA)与全局注意力(Full Attention)之间进行分层混合:绝大多数层仅计算局部窗口内的注意力,只有少量关键层保留全局视野。理论上,这种结构能够将 Attention 的计算复杂度压低到接近线性,同时依然维持对长程依赖关系的建模能力。
但理论上的架构优势,并不会天然转化为真实线上系统中的效率优势。一方面,Hybrid SWA 显著增加了 KVCache 缓存命中、前缀匹配以及 Full / SWA 双语义一致性维护的复杂度;另一方面,在真实工程系统中,多级存储的数据搬运、异步 prefetch 与调度不一致,分布式 cache 状态难以对齐,共同使理论收益难以直接兑现。
除了 Hybrid SWA,MoE 对分布式调度与负载均衡提出了更高要求;多模态 Encoder 在大图、长视频场景下的吞吐瓶颈同样亟待突破。此外,调度策略、Prefill / Decode 执行链路等通用环节的优化也不可或缺。本文记录的,正是围绕 MiMo-V2.5 系列模型的一次推理系统全链路工程化实践,覆盖 KVCache 管理、分级缓存系统、SWA 前缀缓存树、调度策略、Prefill / Decode 执行链路以及多模态优化,系统性地将架构的效率潜力(尤其是 Hybrid SWA)兑现到生产环境中。
一、Hybrid SWA 架构的推理效率优势
在具体讨论优化工作之前,有必要先量化 Hybrid SWA 的效率上界——这既是架构选择的出发点,也是后续所有系统优化的理论基准和理论上界。
1.1 计算量分析
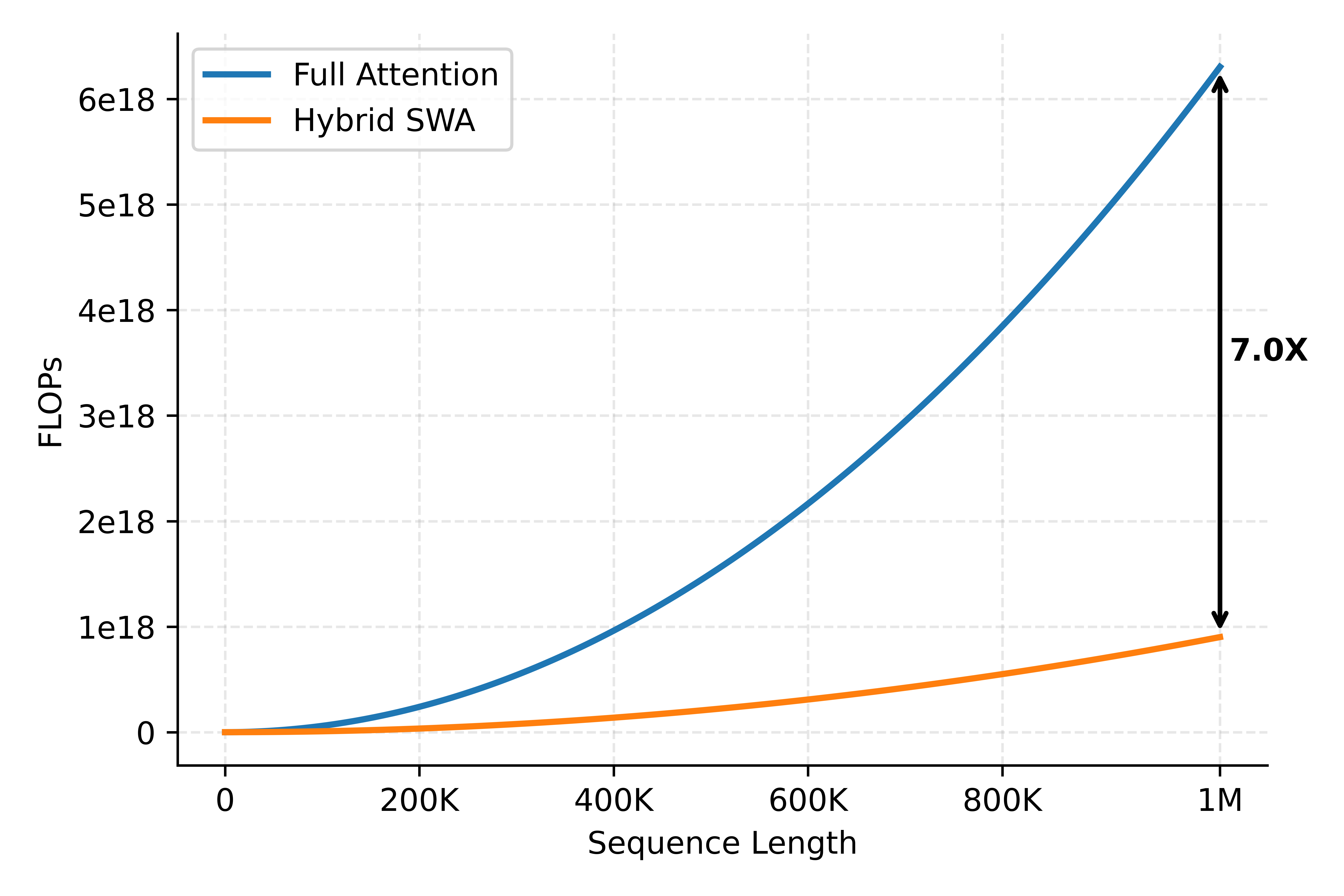
以 MiMo-V2.5-Pro 为例,该模型共 70 层,其中 10 层为 Full Attention,其余 60 层为 SWA,并且 SWA 的滑动窗口大小是 128。与 Full Attention 相比,Hybrid SWA 的计算量如图所示。SWA 层占比为 6/7,因此 Hybrid SWA 架构的计算量约为 Full Attention 的 1/7。在 Chunk Prefill 场景中 Prefill 近似 compute-bound,该差距基本等价于 Prefill 成本的理论缩减。
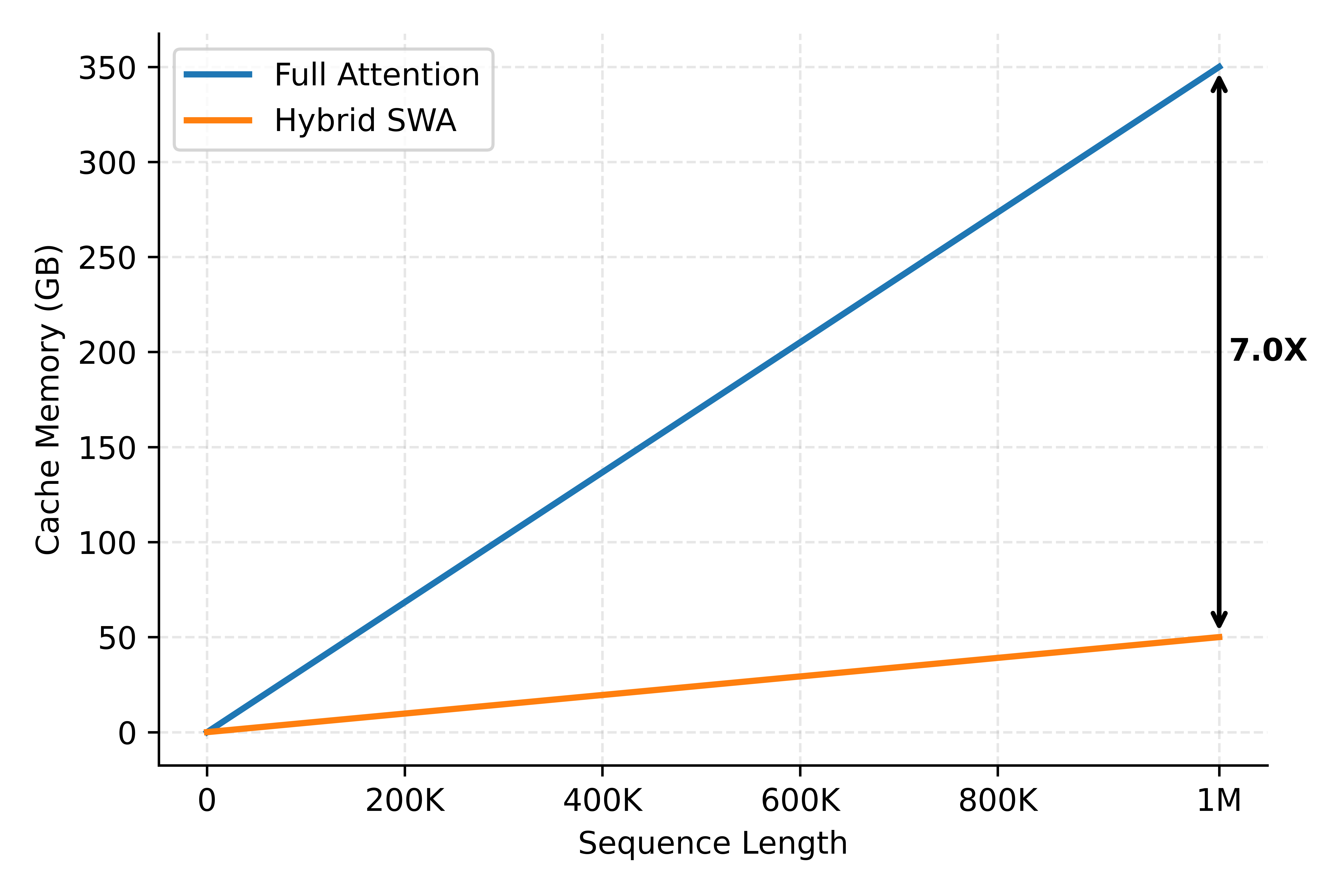
1.2 KVCache 存储分析
由于 SWA 层仅需保留滑动窗口内 KV,无需存储全序列,因此 KVCache 占用同样下降至接近 1/7。Decode 阶段近似 memory-bandwidth-bound,其延迟正比于模型参数加 KVCache 的读取量。在长序列下,KVCache 的体积可能远超模型参数,因此 KVCache 存储的减少几乎直接等价于长序列场景下 decode 成本的降低。
不同模型架构的 KVCache 存储有很大差距,访存模式也存在差异,以下是对各个国产模型估算的 KVCache 大小,可以看出 MiMo-V2.5-Pro 和 MiMo-V2.5 在 KVCache 上位列国产模型第二,仅次于 DeepSeek-V4-Pro 和 Flash。
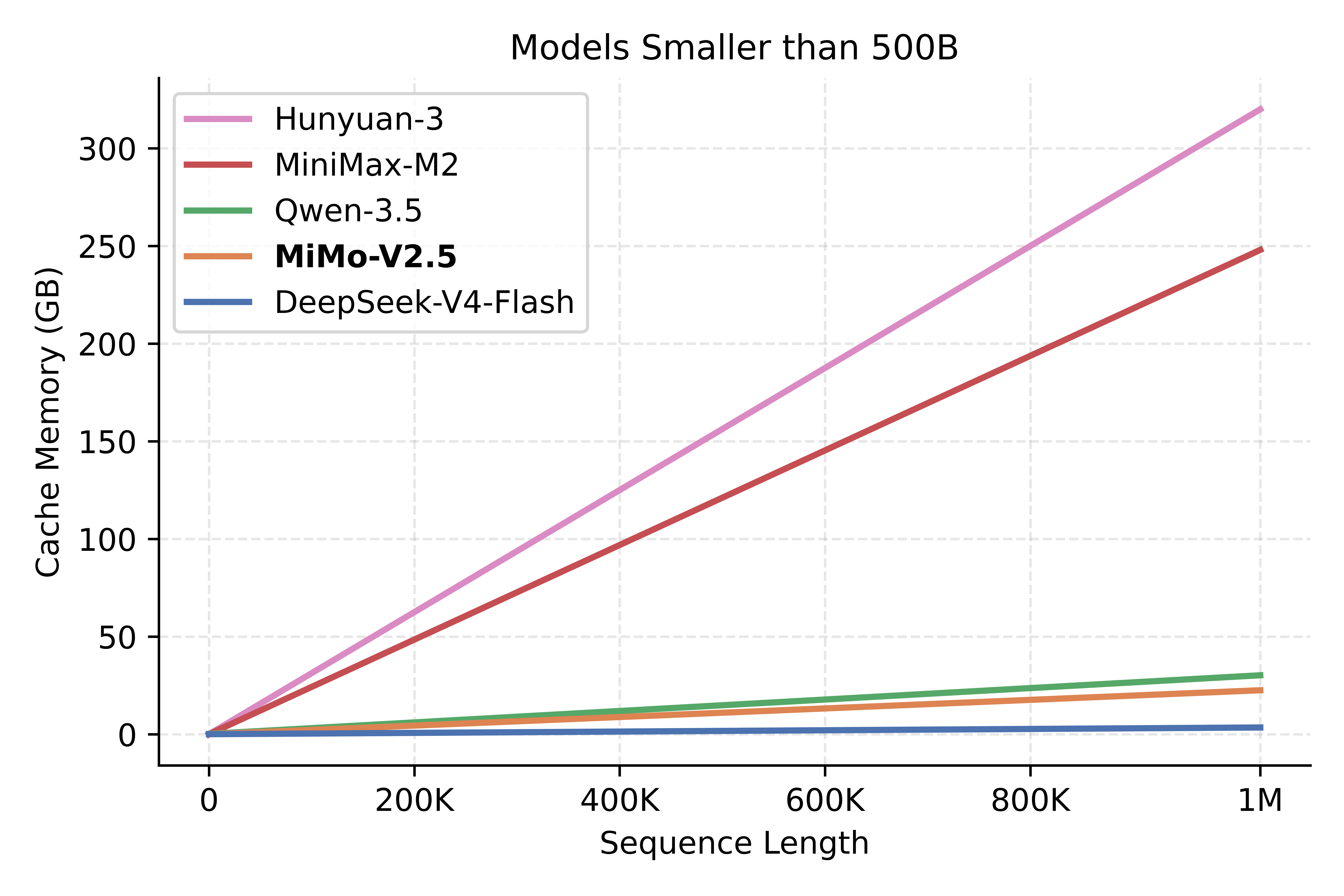
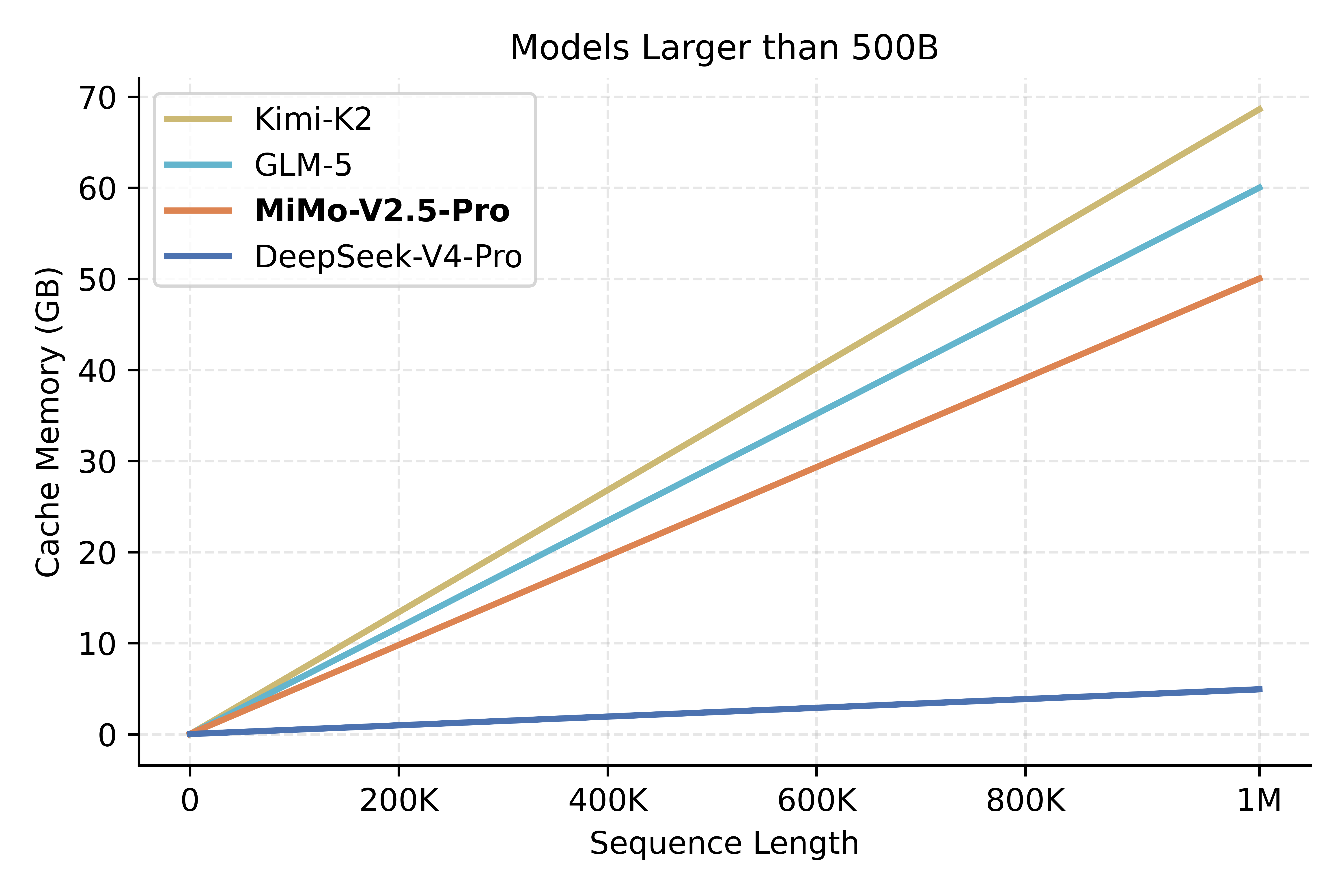
需要注意,实际成本差异并不严格等价于 KVCache 规模比例,因为还存在与序列长度无关的固定计算与访存开销。但在长上下文场景下,整体趋势保持一致:短文性价比接近,序列越长推理成本优势越大。
二、KVCache 系统重构
MiMo-V2 和 MiMo-V2.5 系列作为较早采用 Hybrid SWA 架构的模型,但在当时,无论是主流开源推理框架还是缓存系统,对 SWA 的支持都并不完整。在 MiMo API 上线之初,我们选择了 SGLang v0.5.5 作为服务后端的 codebase,接下来马上就遇到一个严峻的考验,在当时的版本,SGLang 的 HiCache 不支持 SWA,或者说早期的 SWA 支持是以“存储 Full KVCache 的代价来兼容 SWA”的方式实现的。虽然有一些临时方案可以让 SWA 更加可用,但是我们还是希望做一套上限更高并且更好用的 KVCache 系统。
2.1 SWA KVCache 管理
KVCache 双池
Hybrid SWA 带来一个核心存储矛盾:Full Attention 层需要保留全序列 KV(O(N)),而 SWA 层仅需维护滑动窗口内 KV(O(W))。但在传统单一 KV pool 设计下,系统必须按 O(N) 为所有层统一分配显存,使 SWA 的窗口稀疏性无法被利用,实际存储效率退化为 Full KVCache 的近似实现。
为解决这一问题,一种很自然的想法是将 KVCache 拆分为 Full Attention 与 SWA 两个独立池,并在系统层进行统一抽象:
- 物理层面:分别维护 Full KV pool 与 SWA KV pool,SWA pool 仅按窗口大小配置容量,并支持基于 window 的独立 eviction,从而将 SWA 存储严格限制在 O(W) 规模;该机制同样延伸至 L2 与 L3 存储层级。
- 逻辑层面:对上层(前缀树、调度器与传输协议)仍暴露单一序列视图,由 Full Attention 索引作为权威索引,并维护 Full → SWA 的映射关系,实现透明分层存储。
- 调度约束:系统在接入请求时同时校验 Full KV 与 SWA KV 的容量约束,避免单一维度的资源误判。
- 数据搬运:跨层传输仅基于 SWA mask 进行,确保只搬运有效窗口内数据,避免冗余带宽占用。
通过上述设计,SWA KVCache 在系统层面实现严格 O(W) 存储约束,使整体 KVCache 容量效率提升约 7×,从而真正释放 Hybrid SWA 的结构优势。主流推理框架也都采用了类似的实现方案。
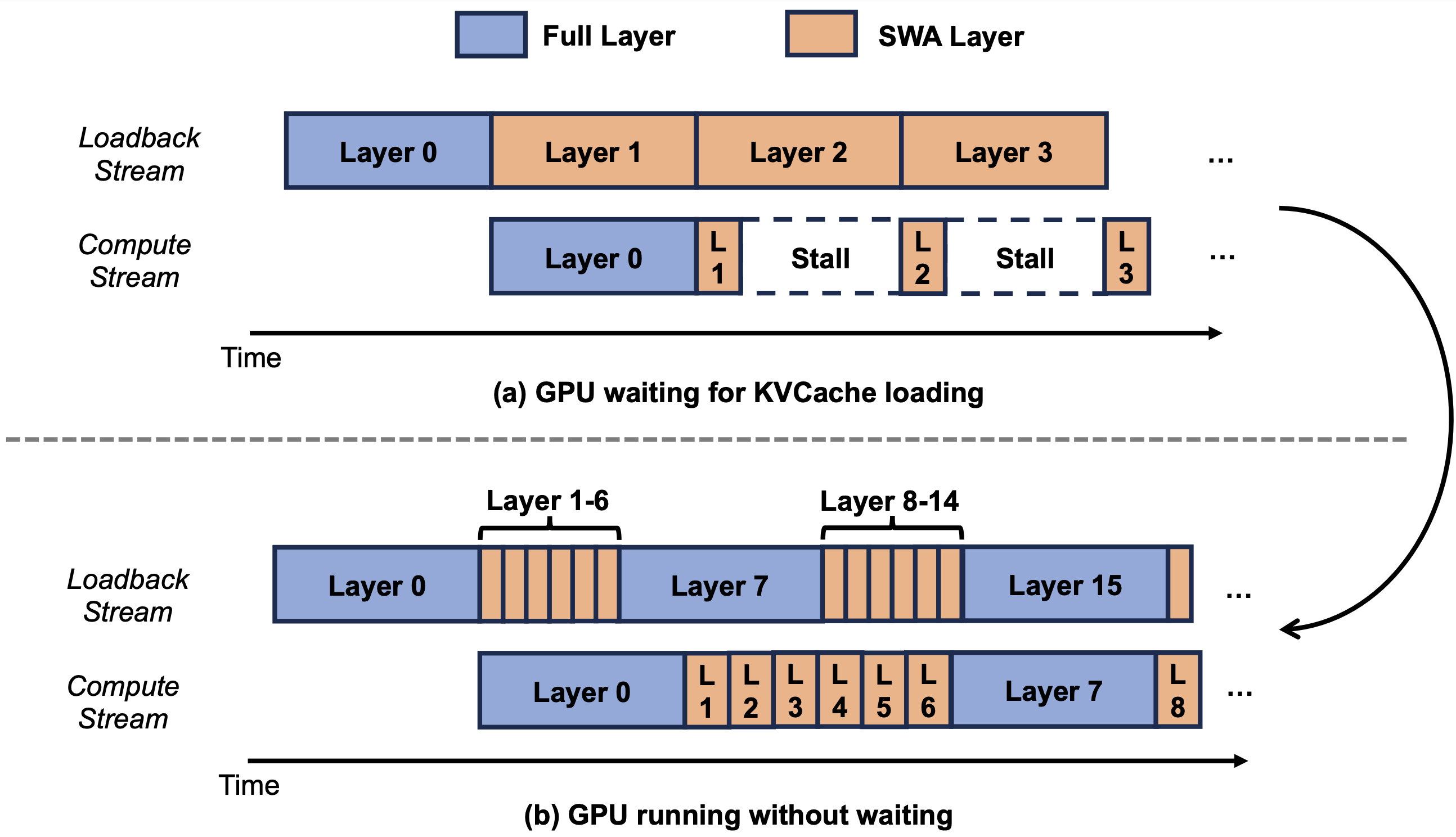
KVCache 按层异步拉取
在 SWA KVCache 存储优化实现后,SWA 层只需要 prefetch 极少量的 KVCache,这使得从 Host prefetch KVCache 到 Device 的过程通过 layerwise 粒度的调度就能实现完美的 overlap。从而在推理过程中对 Cache 读取的成本接近于 0。
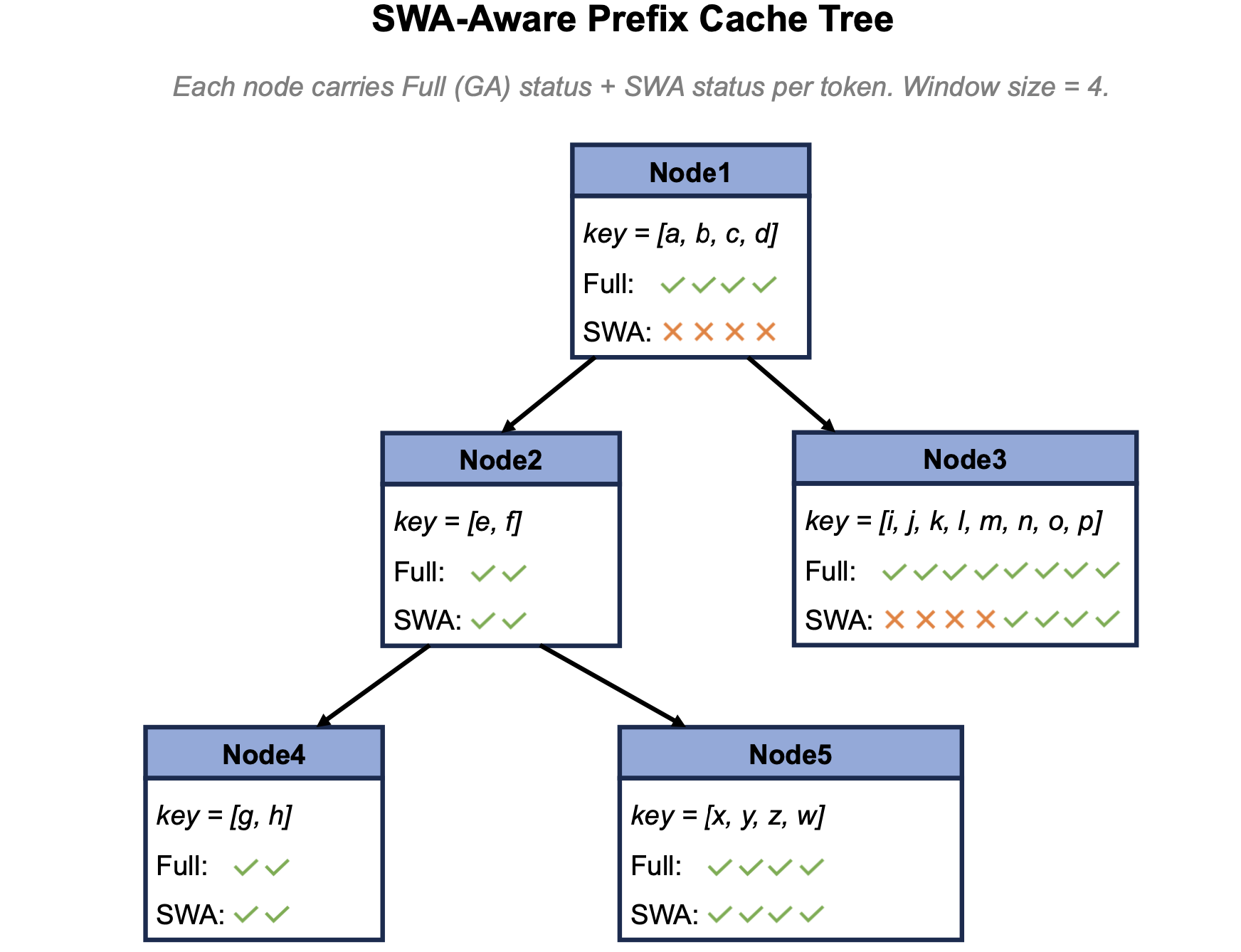
SWA-aware 前缀缓存树
传统 RadixAttention 的命中规则建立在一条朴素假设上:token 序列相等 → KV 也相等。这条假设在 Full Attention 模式下成立——只要两条请求共享同一段 token id,它们对应的 KV 就一定还在 pool 里,可以直接复用。
但在 SWA 模式下这条假设被打破了。原因在于:前缀树的逻辑生命周期,与 SWA KV 的物理生命周期并不一致。前缀树节点的长度并不受 SWA 窗口约束。一个节点的序列长度既可能短于窗口,也可能远长于窗口;而节点还会随着请求合并、分裂、移除不断变化。于是,一个前缀树节点虽然逻辑上仍代表一段完整 token 序列,但它对应的 SWA KV 可能只剩最后一部分,甚至已经完全不存在。如果前缀树仍按“token 相等就命中”的规则给出复用长度,调度器拿到的可能会是一段“尾部 KV 已蒸发”的伪命中——后续 attention 计算会读到无效或被覆盖的 slot,直接影响模型效果。
要让前缀复用在 SWA 模式下保持正确且高效,需要从三处改造前缀树的语义:
- 匹配规则升级为“窗口安全长度”:除了 token 相等,还要保证尾部至少 W 个 token 在 SWA 池里仍有有效 slot。匹配长度被裁剪到这条新边界——越过它的部分按 miss 处理。这样保证命中段拿出来的 KV 一定都有效。
- 淘汰路径与请求生命周期绑定:长 prefill 的每个 chunk 完成、请求结束、decode 每生成一定数量 token,都触发一次窗口外 SWA 释放。这保证 SWA 池在长上下文 / 长输出任务中占用恒定在 W 或 chunk 量级,而不是随序列长度增长。
- 节点同时承载两套索引:每个前缀树节点要记录两份信息—— Full Attention 段索引(决定逻辑顺序、参与 Full Attention 层计算)和 SWA 段映射(决定窗口安全性)。淘汰时也要分别管理:可以单独淘汰窗口外的 SWA 段而保留 Full Attention 段(让前缀仍可被全 Full Attention 层复用),也可以整段淘汰。
SWA 把 KV 体积压到 1/7 是容量层面的收益,命中率则是复用层面的收益。两者乘起来才是 prefill 阶段实际计算成本的曲线。引入“窗口安全长度”匹配规则后,同样 token 容量的 KVCache 命中率理论上是小幅度下降的,但同样存储容量下的 token 数量达到数倍,实际命中率大幅度提升。
KVCache 命中率提升优化
HiCache 三级都改造为 SWA-aware 后,device、host、storage backend 端各自维护一套“哪些位置有有效 SWA”的状态,而 HiCache 的搬运链路是异步的、跨部署的 Cache 是各异的、跨 session 的共享前缀的长度也是各异的——这意味着各端的 Full Attention Cache、有效 SWA 索引很容易出现不一致的现象。根据 SWA-aware 前缀缓存树的匹配规则,如果一个序列在 Full Attention Cache 上能命中、但在 SWA Cache 上不能命中,会带来严重的匹配长度裁剪,裁剪得越多,需要重算的长度越长,SWA Cache 优化效果就越低。因此,我们针对不同场景做了分布式一致性和缓存命中率的优化:
- Device 端完备,host 端空缺:当 L3→L2 预取出于带宽与延迟权衡仅拉入序列尾段、或 L1 前缀树重组后未同步到 L2/L3 时,会出现 device 端完备但 host 端空缺的问题。对此,我们在前缀树发生节点合并、prefill 完成等时间节点,主动检查 device / host 两套 SWA 占用的差集,在 host 端的 SWA pool 里补分配 slot,把 device 的 SWA KV 异步 D2H 写入。
- Host 端完备,device 端空缺:等到下一次 H2D 完成自然对齐,无需主动修补。
- 高频序列 L3 前缀过期:长序列头部因高频访问持续存在于 L1/L2,加上 Cache 亲和性使相同前缀请求路由到同一节点,L3 中的 Cache 因长期未被直接访问而可能被 storage 淘汰策略清理,从而导致全局高频序列的 L3 Cache 被提前释放、跨机复用大打折扣。对此,我们在访问到 L1/L2 上的 Cache 时,以一定周期 query L3 Cache,避免淘汰。
- 中短序列的 SWA 留存策略:对于中短序列的 SWA,我们根据用户请求 pattern,固定在某些长度留存相对稠密的 SWA KV Cache。尽管调高 SWA 的密度会使得整体 KV Cache 中 SWA 的比例上升,但能直接惠及多用户共享 system prompt 等场景。
通过上述优化,我们把 KV Cache 容量层面的扩增真正转化为高有效命中长度,使跨 session 长前缀复用成为可能,尤其利于 agent 长会话、多用户共享 system prompt、多次访问同一 codebase 的 tool call 等场景。
2.2 GCache:高性能分布式缓存基础设施
GCache 是小米存储团队开发的高性能通用缓存,它是构建存储“训推一体”体系重要的一环。早期在训练场景下,存储团队意识到一些开源的缓存项目对分布式文件系统的加速效果有限,无法把性能发挥到极致,因此便开启了自研的道路。之后,随着 MiMo 大模型发布,推理服务上线运行,团队也将 GCache 改造成立独立的存储产品,用于模型分发、和作为推理引擎的 L3 KVCache。
GCache 同时支持文件和 KV 语义、支持 内存 / 磁盘 / 远程 的多级缓存,具备 shm 内存持久化和全链路零拷贝能力,支持高并发非阻塞 IO 和 RDMA 通信等高级特性,满足了上层业务对高吞吐和低延迟的性能要求,同时具备良好的可扩展性。
架构设计
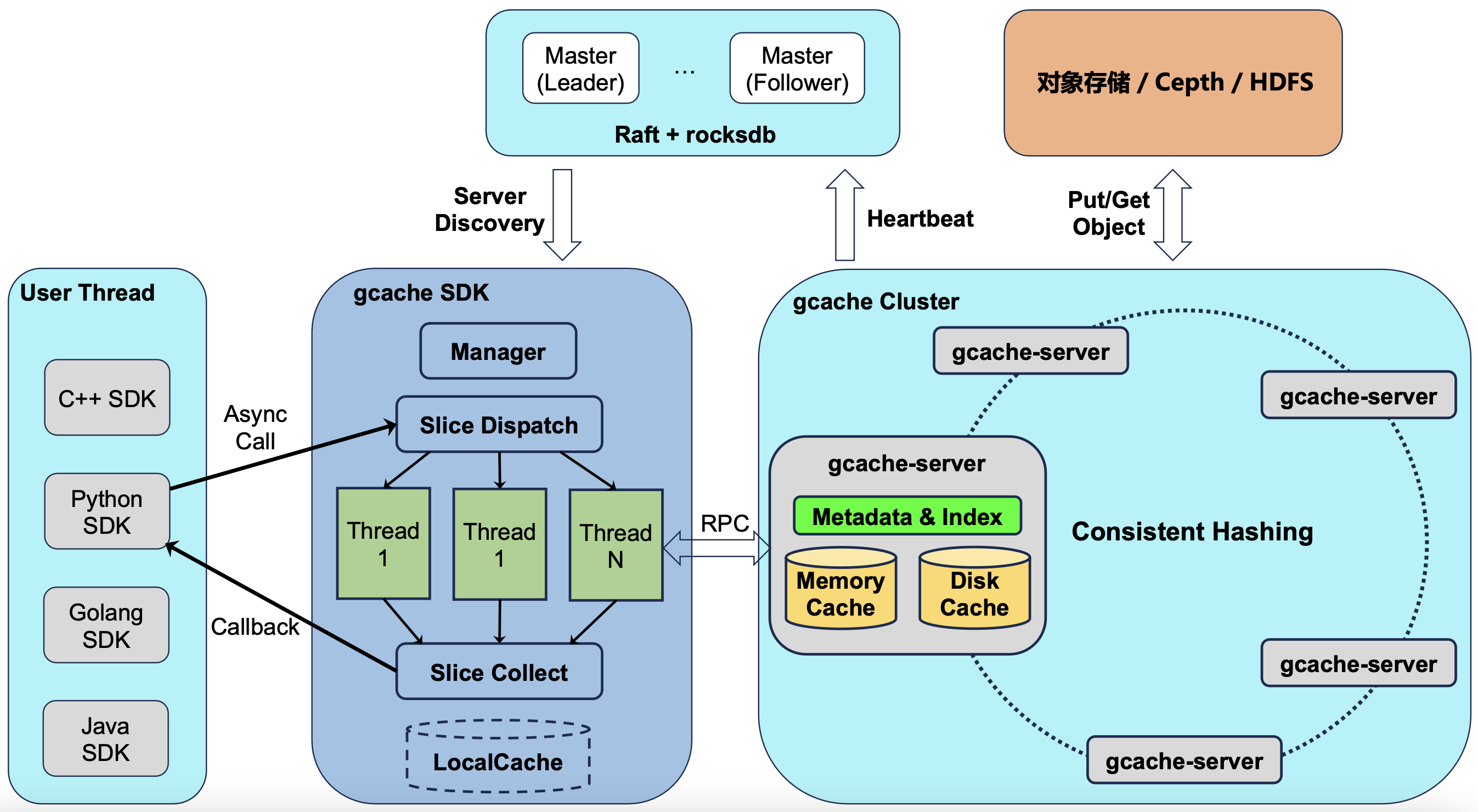
GCache 具备几个特点:
- 非中心化的元数据管理方式,使得集群规模可以不受限制扩展:
- 对 key 计算一致性哈希,确定存储位置。
- Master 采用 Raft 高可用部署。但 Master 只负责管理心跳和服务发现,IO 路径不经过 Master。
- 服务端同时支持内存和磁盘缓存:
- 内存的冷数据会淘汰到磁盘,磁盘的热数据会提升到内存。该模式对推理场景十分友好,自动保证了活跃 session 的性能,也降低了长时间未启动 session 的成本。
- 内存支持持久化到 shm,重启服务不丢缓存。
- 支持平滑扩容或缩容机器,期间不丢缓存。
- 提供多语言 SDK,启动专属线程,将用户请求进行切片和派发:
- 不占用用户线程的资源;切片提高并发,将 IO 大小控制在对 RDMA 友好的范围内。
- 线程以异步模式回调,可灵活控制回调粒度,如单个 kv 级、batch 级、或者 CUDA stream 级。
网络优化
目前主流的 GPU 机型,都配置了 8 张 400G 高性能网卡,然而,即便是考虑了 PD 分离部署,现阶段的推理框架还是很难跑满网络带宽,以至于业界出现了要给网卡减配以便降低成本的声音。
为了充分发挥出高网的能力,GCache 优先使用 GPU 网卡而不是前端网卡进行通信,并在通信模块上做了大量优化,如 NUMA 绑定、同轨亲和等。在具体性能指标上,使用 1MB 大小的 IO,单进程的 RDMA 读吞吐可以达到 170 GB/s,而延迟只有 280 us;在 GDR 场景下,由于 HBM 的带宽更高,单进程可以达到约 350 GB/s,足以满足推理框架对通信的性能要求。
存储成本优化
2026 年无疑是业界对存储成本较为敏感的一年。不同于其他友商使用存储专用机型,GCache 优先采用在 GPU 机器上混布的方式,接管了 Prefill 和 Decode 节点的部分内存,和机器自带的数块 NVMe SSD,额外的存储成本为 0。
稳定性保障
由于是混布,GPU 机器的高故障率成为了摆在稳定性前的一道门槛。上线以来,GCache 基本上每天都会遇到 server 所在的机器故障。首先,团队花了大量时间和精力加固代码的故障处理逻辑;其次,由于 key 是一致性哈希全打散,通过对 session ID 进行提前逻辑分组,也减少了故障半径;最后,结合底层平台提供的硬件检测功能,提前发现故障,使用自动化流程进行数据迁移。对于极少量突然宕机,来不及提前处理的,通过设置较低的 SDK 超时时间,让推理框架及时感知 miss 并进行重算,使得前台的推理流程不会受到较大影响。
基于上述工作,GCache 得以在混布状态下一直保持单副本存储,而不用使用多副本手段提升可用性,这也是存储成本较低的重要原因之一。
2.3 针对缓存命中率的讨论
得益于前述针对 SWA 在 KVCache 上的优化——更低的存储占用,辅以更加稳定的大容量 GCache 作为 L3 存储——我们得以显著延长 Cache 的 TTL(Time-To-Live),并由此大幅提升 KV Cache 缓存命中率。KVCache 的淘汰本质上源于存储容量约束。当容量趋于饱和时,系统须优先保留新请求产生的 KV Cache,并按 LRU 等策略淘汰历史中被访问的条目,这直接导致某一 context 在数小时后被复用时往往已无法命中。SWA 的极小存储占用使得相同成本下可承载的并发请求缓存量成倍提升,而大容量 L3 则以低成本进一步扩充了可用容量——存储空间越充裕,KVCache 被迫淘汰的压力越小,留存时长自然越长。TTL 越长,历史 context 的可命中窗口越宽,Cache 命中率随之水涨船高。此外,SWA 更小的带宽传输压力虽不直接作用于 TTL,但显著降低了多级存储间的数据搬运开销,为整套缓存体系的稳定高效运转提供了保障。
模型上线以来,我们在服务端持续观测到:在主流优质 harness 框架下,服务端 KV Cache 命中率平均可达 93%;对于高强度、长周期使用的个人用户,该指标更可攀升至 95% 以上乃至更高。后续我们将持续迭代 SWA 的 KV Cache 管理逻辑,并联合更多 harness 框架推进 harness-inference 的 co-design,以进一步优化缓存命中率上限。
三、调度优化
早期 SGLang 社区的 router 服务还尚未完全成熟,多个实例间没有做数据共享,如果某个 router 服务意外故障或者请求路由到不同的 router 服务,会出现 KVCache 调度回退的问题。为了解决这个问题,以及确保在大规模集群部署中的高可用性,小米开发了可动态扩展的无状态调度器 LLM-Router,通过使用 Redis 作为中心化存储,避免了单服务故障后的 KVCache 调度回退现象,从而更稳定的保证了缓存命中率。
3.1 KVCache 与负载亲和调度
由于 HiCache 对于 L2 的命中率非常敏感,如果 L2 没有命中,就需要去 L3 查找并拉取 KVCache,等待拉取结束后才能对该请求进行推理。从 router 侧提升 L2 命中率可以降低不必要的同步等待,从而直接提升吞吐性能。
Router 中通过将分发过的请求维护在 Radix 前缀树中,实现了 KVCache 亲和调度。在多个 Prefill 实例间优先选择已经缓存当前请求前缀的节点,并同时兼顾负载均衡来避免热点倾斜。该策略上线后,将 L2 的缓存命中率提升了约 25%,单机输入吞吐提升了约 30%。其核心公式大致为:
# 选择 score 最大的 worker,含义:缓存命中率高 + 负载低 = 得分高 = 优先选择
score(worker) = matchWeight × prefix_match_percentage − normalized_load3.2 TTFT 优化
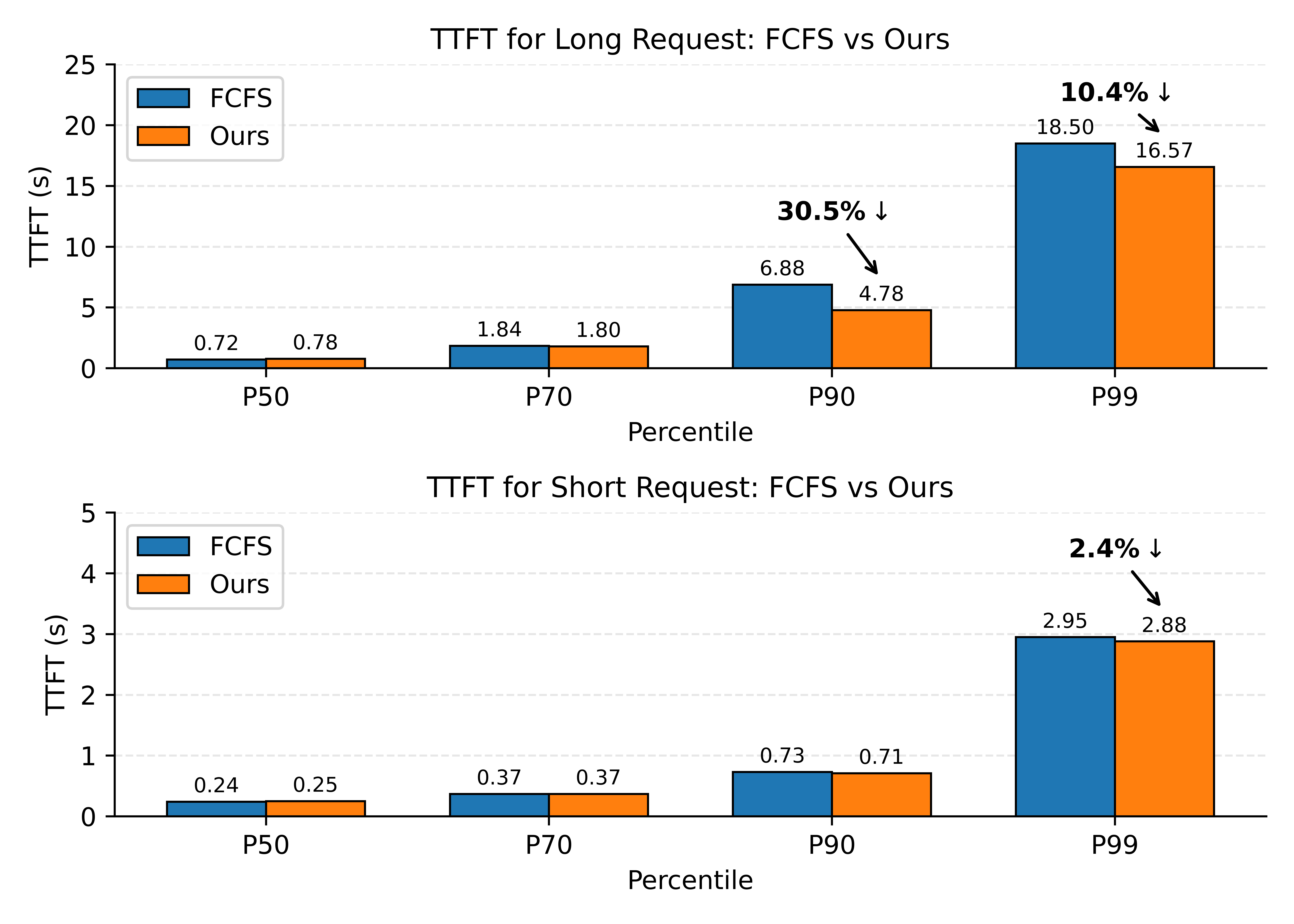
当模型服务出现排队现象时,传统的 First Come First Serve 策略没有考虑较高命中率和较低命中率请求的优先级关系,使得命中 Cache 更多但真实计算 token 更少的请求有可能等待 Cache 命中率更低的请求推理结束后才能开始推理。整体服务的 TTFT P99 会变得异常的长,拖慢整体吞吐的平均性能。
为了解决这个问题,在 waiting 队列选择优先执行 prefill 服务时,Router 侧优先调度真实计算 token 数更少的请求,避免这些原本计算时间很短的请求被阻塞而导致 P99 过度劣化的问题。同时,这种策略会导致某些请求长期得不到调度的饥饿现象,所以我们还增加了等待时间的惩罚机制来平衡这一现象。结果表明,该策略对于较短的请求并不会降低服务质量,而对于较长的请求,该策略最高可以将 TTFT 的 P90 指标降低 30%。
四、Prefill 优化
4.1 分布式配置
理论上,prefill 阶段 EP(Expert Parallelism)越小,性能与吞吐越优,主要体现在三方面:跨的机器更少,跨机通信开销更低;DP(Data Parallelism)数更少,DP 间 attention 负载差异对性能的影响更小;每台机器承载的 expert 数量更多,MoE 负载均衡性更好。但 EP 大小受显存约束,需满足模型参数与 KVCache 的显存占用。早期 SWA KVCache 需保存所有 token 的 KVCache,导致 EP 被迫偏大;优化后仅需保存 SWA 部分 token,我们将 EP 缩减至原先的 1/2,端到端性能提升约 40%。后续我们将继续探索面向 Hybrid SWA 结构的 PP(Pipeline Parallelism)优化,进一步降低 EP 大小、提升整体吞吐。
4.2 长度分桶策略
MiMo-V2.5 系列的 Hybrid 架构相比纯 GQA 结构计算效率显著提升,但吞吐仍随序列长度增加而明显下降。下图展示了 Chunked Prefill 中,固定计算 16K token、搭配不同长度前缀时的吞吐:
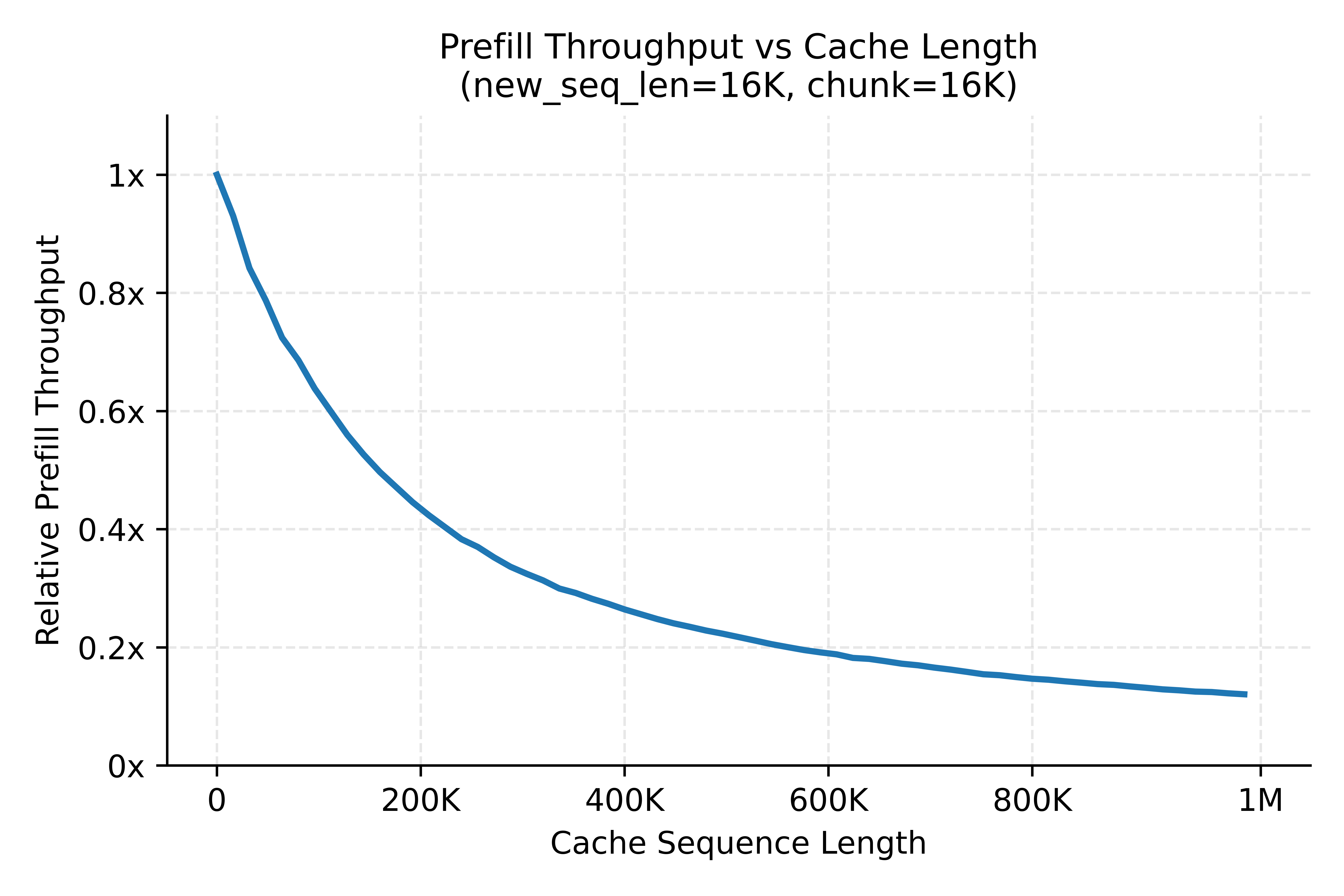
Agentic 场景下,超长请求大多来自于多轮 agent 交互,一般带有大量前缀缓存。当长度差异显著的请求被调度至同一模型实例时,短请求会被长请求拖累、降低整体吞吐,主要体现在两种场景:
- DP-Attention 同步:多 DP 在每层 attention 计算后需集合通信以同步进入 MoE 阶段的计算,同一 EP 组内的多个 DP 上若同时存在长请求与短请求,短请求将被长请求的计算拖慢;
- Chunked Prefill 干扰:不同前缀长度的请求编入同一 chunk 推理时,短前缀请求被长前缀请求的计算拖慢。
为缓解上述负载不均衡问题,我们采用三级长度分桶策略(0–64K / 64K–256K / 256K–1M),将负载特征相近的请求聚合至同一桶内做计算,显著提升了线上 prefill 的平均吞吐。在此基础上,我们当前也正在探索更细粒度、更灵活的分桶机制,以适应线上负载的动态变化。
4.3 MoE 负载均衡
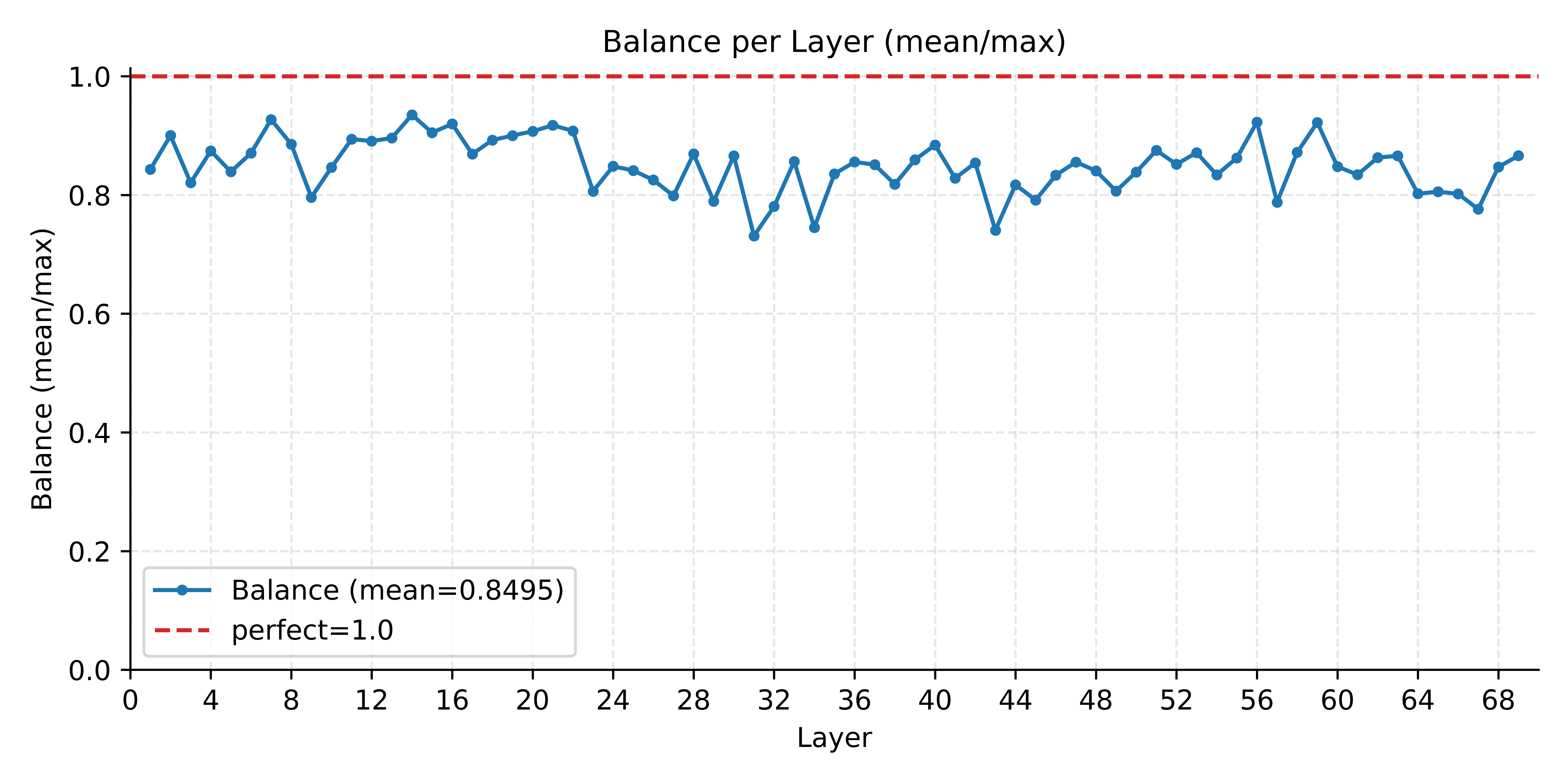
MiMo-V2.5 系列模型均采用 MoE 架构,需要考虑 prefill 阶段的专家负载均衡问题。由于预训练阶段引入了负载均衡的训练目标、且训练较为稳定,模型在训练时已学习到较为均匀的专家分配策略。推理阶段,在未启用任何专家负载均衡策略的条件下,各层平均专家负载度(一层中所有 rank 的平均 token 数与该层 rank 最大 token 数之比)约为 0.85,已处于较优分布水平。因此,我们目前并未引入任何专家负载均衡策略。后续我们将持续监控该指标,根据线上负载模式的动态演进按需引入相关优化。
4.4 解决 NUMA 冲突
部分 Ubuntu 系统的内核 numa_balancing 参数与 SGLang 的 numa-node 配置存在冲突,导致模型推理过程中计算 kernel 间偶发较大执行间隙。多机多卡部署下,各 rank 上该间隙出现位置随机,每次 rank 间同步时都会被最慢的 rank 拖慢整体计算流程,从而显著影响整体推理效率。禁用系统内核的 numa_balancing 参数后问题消除,端到端性能提升约 10%。
五、Decode 优化
5.1 显存优化
Agentic 场景下,多轮对话使上下文持续增长,KVCache 显存占用成为 decode 的主要瓶颈——显存被 KVCache 占满后 batch size 无法扩展,使计算打不满、decode 吞吐受限,只能增加节点承载并发,推高推理成本。为了增大单节点并发,我们做了多个显存优化措施:
- Decode KVCache 完整支持 SWA:KVCache 有效容量提升近 5 倍。
- PD 分离中 KVCache 预分配优化:将尚未启动的请求的 prealloc 过程从 GPU 显存迁移至 CPU 内存,decode 实际启动时才搬入显存,消除资源预占造成的浪费。
- CUDA Graph 显存调优:优化 CUDA Graph 参数减少空间浪费,可用显存提升。
5.2 MTP 优化
MiMo-V2.5 系列模型原生支持 3 层 MTP 加速 decode 输出,但 prefill 阶段此前未开启 MTP,导致 decode 初始 128 输出 token 的 MTP 使用无效的 KVCache、预测接受率极低。由于 Agentic 场景下大部分输出序列较短,该缺陷使 MTP 加速效果大打折扣。通过在 prefill 阶段引入 MTP 支持并对 HiCache L2/L3 进行专项适配和优化,decode 前期 MTP 加速效果显著提升:第 0–128 token 加速比达 2.3×,第 128–256 token 加速比达 1.5×,有效降低了 agentic 场景下的真实 decode 成本。
六、多模态推理优化
基于 SGLang 社区 v0.5.7 EPD 方案,我们围绕 MiMo-V2.5 做了大量 EPD 分离方面的工程优化与稳定性修复,在延时保持不变的情况下,将 Encoder 吞吐提升至 2 倍,目前正在将工作成果回馈 SGLang 社区(issue #24945)。优化前后的 Encoder 性能差异如下表所示:
| QPS | 平均延迟 | P90 延迟 | |
|---|---|---|---|
| 优化前 | 15 | 78.39 ms | 100.76 ms |
| 优化后 | 30 | 80.28 ms | 82.94 ms |
6.1 架构优化
- 多模态 Embedding 数据复制与推理并行:在 Prefill 调度器主循环中,支持 TP 之间多模态 Embedding 数据异步复制,与 Prefill 推理重叠,减少 GPU 空闲时间。
- Encoder 支持数据并行:由于 Encoder 模型较小,设置 TP>1 反而会导致性能下降,因此,Encoder 我们采用 TP=1 部署,同时支持数据并行,方便在单机 8 卡部署和运维。
- Encoder 支持跨请求组 Batch:我们为 EPD Encoder Server 引入跨请求 Batching,通过 Encoder 调度器将并发请求按模态聚合,多个请求的 image/audio 融合成一次 Encoder Forward 再按请求切分返回,解决逐请求编码 GPU 利用率低的问题。
6.2 预处理优化
- 图片 GPU 预处理:大图场景下 CPU 上执行 resize/normalize/patchify 会大幅增加端到端延迟,因此我们将预处理迁到 GPU,消除 CPU 瓶颈。
- 图片并行下载:我们使用多进程并行下载图片和 PIL decode,避免串行下载和 GIL 锁竞争带来的延时。
- 多模态下载和 forward 并行:在早期 Encoder 实现中,batch 之间和 batch 内数据下载和推理都是串行的,导致下载时候 GPU 是空闲的;我们通过消息队列,解耦下载和推理,实现 batch 内下载和推理重叠。
- 视频并行解码:将待抽帧索引均匀切分为 N 个 chunk,并为每个 chunk 创建独立 VideoDecoder 实例多线程并行解码,使 1 小时视频 Encoder 端到端延时从 156s 降低到 23s。
6.3 缓存优化
- Encoder 一致性哈希:多个 Encoder 场景下,Prefill 轮询选择 Encoder,导致多模态 cache 命中率降低。通过一致性哈希,我们将相同请求路由到相同的 Encoder,缓存命中率提升 30%。
- 机内 Embedding 缓存共享:通过共享内存,实现 Encoder 机内多卡之间共享多模态缓存数据,提升缓存命中率。
七、后记
回顾整项工作,MiMo-V2.5 系列模型的推理效率并非来自某一环节的单点突破,而是多维度协同优化的结果。Hybrid SWA 让 prefill 与 decode 同时受益,但未经充分优化的 KVCache 实现反而会在各环节抬高成本。围绕这一目标,我们系统性重构了 KVCache 管理、分级缓存、前缀缓存树,攻克 SWA KVCache 核心问题,优化了调度策略及 Prefill / Decode 链路,并经线上真实场景检验,最终将其理论效率优势真正兑现到生产环境。至此,Hybrid SWA 才发挥出在长文推理上兼具强度与效率的架构优势。再组合 MoE 配置和多模态推理的各种优化,极大程度提高了线上推理服务的性能。
我们在此呈现首篇全面覆盖 Hybrid SWA + MoE + 多模态组合架构的大规模工程落地方案,并将由此节省的成本通过 API 降价回馈用户。同时,我们已将部分优化以 PR 形式回馈 SGLang 开源社区,并将持续推进更多开源计划,希望尽早让工程优化不再成为门槛,使这类兼具强度与效率的复合架构得到更广泛的探索与应用。